.svg)

Who We Are
Apolo Cloud Inc., located at 300 Southwest 1st Avenue, 155, Fort Lauderdale, FL 33301 (“Apolo”), is a U.S.-based AI infrastructure and MLOps platform purpose-built for data centers and telecommunication providers. We enable colocation, retail, and edge facilities to offer white label, secure, scalable, and value-added GPU-as-a-Service solutions. Our platform combines multi-tenant access, resource orchestration, integrated ML development tools, white-glove MLOps support, and seamless integration with customers’ ERP, billing, and support systems. Apolo is hardware-agnostic—compatible with NVIDIA, AMD, and Intel—and is designed to run AI where the data lives, eliminating egress costs and supporting compliance in regulated industries. By bridging the gap between bare-metal infrastructure and full-service AI delivery, Apolo helps data centers transform into competitive AI cloud providers.
Executive Summary
The GPU Cloud & AI Compute Market is rapidly transforming, driven by explosive demand for AI workloads. Enterprises and startups racing to train and deploy large-scale AI models have made GPU-as-a-Service (GPUaaS) a critical enabler.
This Market Research Report analyzes GPUaaS, GPU cloud, bare metal, and other emerging offerings from industry players. The primary objective was to gather precise, real-world data regarding pricing and service terms through direct quote requests for DGX/HGX H100 servers. Beyond GPU pricing alone, we assessed the total cost of services, including storage, RAM, CPUs, networking infrastructure, and additional service fees. This holistic approach was essential to accurately determine the actual cost and value proposition of AI computing solutions available in today's market.
Understanding the nuances of pricing structures and associated service terms empowers stakeholders to make informed, strategic decisions.
Surging Demand: Annual enterprise cloud infrastructure spending reached an enormous $330 billion in 2024, a 22% year-to-year jump, with AI-related services powering roughly half of the growth. With AI adoption accelerating, new entrants are emerging to capitalize on unprecedented demand for cutting-edge GPUs, while hyperscalers are expanding their GPU fleets to keep pace.
Expanding Competitive Landscape: Our research identified 38 providers across specialized GPU clouds, bare-metal providers, marketplace platforms, and hyperscalers. Major cloud providers still dominate in scale, but GPU-focused neo-clouds are growing fast. Many new providers have roots in cryptocurrency mining or high-performance computing (HPC), repurposing infrastructure for AI. This has resulted in a crowded field with diverse strategies, from low-cost community GPU marketplaces to enterprise-grade bespoke services.
Total Cost of Ownership & Hidden Fees: Headline GPU-hour prices do not tell the whole story. Our analysis found that hidden costs can heavily impact the total cost of ownership (TCO). Many alternative providers differentiate by offering more transparent pricing. Smaller GPU cloud players often bundle generous data transfer allowances or flat-rate storage to ensure predictable bills. This trend toward transparent, all-in “no surprises” pricing has become a key competitive factor as businesses seek to avoid the prohibitive cost penalties of legacy cloud billing.
Market Growth & Outlook: The GPUaaS is expected to continue its rapid growth through 2025 and beyond as AI adoption expands across industries. Analysts project the global GPUaaS segment to grow to over $95 billion by 2037. Despite a rising tide lifting all providers, challenges such as GPU supply constraints, high power and cooling requirements, and the complexity of AI workflows persist. These challenges create gaps that innovative providers can fill. Strategic opportunities exist in offering turnkey AI infrastructure (combining hardware, software, and expertise), truly transparent pricing models, and hybrid deployment options for on-premise or private cloud integrations. We anticipate some consolidation of smaller players over the next few years, as well as deeper partnerships between cloud providers and AI firms.
Overview of Research Approach & Methodology
Research Objectives
Apolo initiated this study to gain a comprehensive understanding of the GPUaaS market. The core objective was to compare the total cost of ownership and some qualitative parameters for a specific request – a 16× NVIDIA H100 GPU cluster with high-performance storage and networking.
Methodology Summary
We conducted a structured market survey:
- Provider Identification: First, we compiled a broad list of 38 GPU infrastructure providers spanning all market segments (hyperscale cloud, specialized GPU clouds, bare-metal hosting providers, marketplaces, and other emerging models). This list was designed to cover the full spectrum from large incumbents to niche startups. (See the Competitive Analysis Section for a full list and segmentation of these providers.)
- Standardized RFP Outreach: We prepared a detailed RFP describing the target deployment: 16× H100 GPUs, 20 TB high-speed NAS storage, ~30 TB outbound data per month, 6–12 month commitment. All providers were contacted by one of our software development partners with this identical requirement set in January 2025 via direct emails and provider contact forms. We asked each provider to respond with a proposal or quote, including the following details on their solution: hardware specification, pricing breakdown, data center details, SLA, support services, and additional software.
- Response Tracking: We recorded each provider's response status and gathered data from proposals and any additional correspondence or interviews. We conducted 26 initial calls with sales representatives, followed by 15 technical product demonstrations. Out of 38 providers, 20 delivered formal proposals or pricing quotes meeting the requested specifications, 4 replied but indicated no available capacity, and the remaining 14 providers either did not respond or did not have immediate capacity.
- Data Normalization: We systematically reviewed and normalized the received proposals, along with publicly available information for non-respondents. We tabulated key metrics for each provider, ensuring apples-to-apples comparisons. Where information was missing or unclear, we asked the provider follow-up questions.
Key Metrics Collected
In evaluating provider offerings, Apolo analyzed several key metrics and factors to compare value and capabilities:
- Pricing: We captured detailed pricing for the GPU cluster, including per-GPU hourly rates (on-demand and any longer-term discount rates), storage costs (per TB/month), data egress fees, and any one-time or setup fees. We calculated each provider's total monthly cost for the full 16×H100 cluster (with 20 TB storage and 30 TB egress assumed), enabling direct TCO comparisons. We noted discounts for commitments (e.g., monthly or annual leases vs. hourly) and any volume pricing adjustments for 16 GPUs.
- Data Center Locations & Tier: The geographic location(s) where the GPUs would be hosted and the data center tier or reliability rating were recorded. This includes region (e.g., US East, EU West, Asia) and facility tier (Tier III, Tier IV, etc., if stated). Location is relevant for latency and data governance considerations, and tier indicates the facility's expected uptime/redundancy. Providers that offered multiple location options were noted, as was any flexibility for multi-region deployments.
- Uptime Guarantees (SLA): We reviewed Service Level Agreements or uptime guarantees associated with the service. Many providers offer a contractual uptime (e.g., 99.9% or 99.99% availability). We captured whether each provider has a formal SLA for the GPU cluster, and if so, the uptime percentage and any remediation (credits/refunds for outages). This is a key quality indicator; a higher SLA (or use of Tier III/IV data centers) gives more confidence in reliability.
- Technical Specifications: We gathered details on the proposed hardware and infrastructure setup. This included the server hardware model and configuration (e.g., whether using NVIDIA HGX or DGX systems that pack 8 GPUs with NVLink or standard servers with GPUs connected via PCIe), the CPU and RAM provisioned alongside the GPUs, and network connectivity. Notably, for multi-GPU clusters, high-speed interconnects (like NVIDIA InfiniBand or Spectrum-X networks) can significantly impact performance for distributed training – we noted if such features were present. We also recorded storage technology (NVMe SSD, network file system, etc.) and any performance specs provided (I/O throughput, etc.).
- MLOps & Software Support: We noted the availability of any integrated software platform or managed services on top of the raw infrastructure. For example, hyperscalers integrate GPUs with managed ML services, and some specialized providers offer ready-to-use environments (pre-installed AI frameworks, container orchestration, etc.). We captured whether providers offer features like web portals for job submission, one-click Jupyter notebooks, or container orchestration (Kubernetes with GPU support). Even if a complete platform isn’t offered, we noted if basic frameworks/drivers come pre-installed to ease setup. This factor indicates how “turn-key” the solution is – whether the customer must self-manage a lot or can leverage built-in tools for ML workflows.
- Support & Value-Added Services: We gathered information on support models and any additional services. This includes whether 24/7 support is available, whether support is included or costs extra, and if any professional services (architecture guidance, managed model training assistance, etc.) are provided. Some providers included onboarding help or periodic consultations in their offer. We also noted unique value-adds (e.g., specialized security features, custom networking options, or carbon-neutral energy usage for sustainability, as these were sometimes highlighted).
Market Overview: GPU Cloud & AI Compute Market
What is GPU-as-a-Service? GPU-as-a-Service refers to on-demand access to Graphics Processing Units in the cloud, allowing companies to rent time on powerful GPU hardware rather than own it. GPUaaS offerings range from virtualized instances on public clouds to dedicated bare-metal servers in colocation data centers. In all cases, the customer can leverage high-end GPU compute, scaling usage up or down as needed. This model provides flexibility to access hundreds or thousands of GPU hours on demand, without the capital expenditure and lead time of procuring physical GPU clusters.
Market Size & Growth: The GPUaaS market has grown explosively in recent years, piggybacking on the broader cloud computing boom and the AI revolution. Forecasts project this segment to exceed $95 billion by 2037. This aligns with the launch of OpenAI’s ChatGPT (late 2022) that triggered many enterprises to increase AI R&D, in turn requiring far more GPU resources. As a result, demand for GPUs – especially the NVIDIA A100 and H100 – has often outstripped supply in 2023-2024, with cloud providers scrambling to add capacity.
Key Market Drivers: Several factors fuel this growth in GPUaaS: (1) Generative AI explosion – the race to develop larger AI models (for language, images, etc.) is compute-intensive, driving organizations to seek scalable GPU clusters in the cloud. (2) Cost and flexibility advantages – few companies can afford to purchase dozens of $30K+ GPUs; cloud rental provides access on a pay-as-you-go basis. (3) Emergence of new players – venture-funded startups have significantly increased supply and innovation (e.g., specialized AI clouds), making GPU compute more accessible. (4) Enterprise AI adoption – beyond tech companies, traditional enterprises are now implementing AI projects (analytics, predictive models, etc.), creating new demand for GPU infrastructure often via cloud or hosted solutions. (5) Maturing software ecosystems – frameworks like TensorFlow and PyTorch, and platform tools (MLOps pipelines, etc.), have made it easier to utilize many GPUs effectively, unlocking more use cases and thus more demand.
In summary, the GPUaaS market in 2025 is robustly growing but also highly dynamic. Demand is abundant and rising, which has lowered the barrier for many new entrants to find customers. However, competition is intense on both price and feature fronts. For enterprise customers, the landscape offers more choices than ever: from renting a fully managed AI supercomputer on hyperscaler to leasing a bare-metal server in a European data center to tapping a decentralized pool of GPUs for pennies on the dollar. The following sections delve into GPUaaS tech stack, pricing models, how the competitive landscape is segmented, and provide detailed profiles of the key players shaping this market.
Technical Deep Dive
The Complexity Beyond Compute: Understanding the AI Cloud Ecosystem
Successfully deploying and managing AI workloads, especially at scale, involves far more than just accessing powerful GPUs. Building or utilizing an effective AI Cloud or GPUaaS offering requires navigating a complex ecosystem. Beyond the core compute elements (GPUs, CPUs, memory), critical components include high-throughput, low-latency networking (like InfiniBand or RoCE) for distributed tasks, high-performance storage solutions (parallel file systems, NVMe fabrics) capable of feeding data-hungry models, and sophisticated software layers for orchestration (like Kubernetes or Slurm) and MLOps (covering the entire model lifecycle). Added to this are essential considerations like robust security measures, compliance adherence (GDPR, HIPAA, etc.), transparent monitoring, reliable support, and potentially intricate billing integrations. Achieving success in this landscape necessitates significant internal expertise or strategic partnerships across various technology domains – from hardware integration to specialized software platforms and managed services. This deep dive explores the key technical layers influencing provider choice and solution design.
GPU Hardware and Configuration: More Than Just the Chip
While the NVIDIA H100 Tensor Core GPU remains a dominant force, understanding how it's deployed is crucial. Providers utilize different form factors: high-density SXM modules on HGX baseboards enable direct, high-bandwidth NVLink/NVSwitch connections between GPUs within a server, which is ideal for large model training. Alternatively, PCIe card versions offer more flexibility in standard servers but typically rely on the slower PCIe bus or potentially pairwise NVLink for inter-GPU communication. For workloads scaling beyond a single server (e.g., >8 GPUs), the inter-node network fabric becomes paramount. Leading providers often leverage NVIDIA Quantum InfiniBand or specialized Ethernet fabrics (like AWS EFA) to minimize latency and maximize bandwidth. In contrast, some providers might only offer standard Ethernet (10-100 Gbps), which can severely bottleneck multi-node training performance. Key questions for users: Does the instance use SXM with NVSwitch? What is the node-to-node interconnect fabric and its speed?
Hardware Insights: Balancing Compute, CPU, and Memory
For many single-node tasks (inference, smaller model training), the performance difference between PCIe and SXM H100 might be negligible. However, for cutting-edge distributed training spanning multiple nodes, solutions featuring dense 8-GPU nodes with NVLink/NVSwitch and high-speed inter-node fabrics (like InfiniBand) offer significant advantages. Beyond the GPU, the surrounding configuration matters. Some providers bundle powerful CPUs and large amounts of RAM with each GPU (potentially increasing cost but beneficial for CPU-heavy preprocessing or data loading), while others offer leaner CPU/RAM configurations targeting purely GPU-bound tasks at a lower price point. Evaluating the CPU cores, RAM capacity, and local storage (type and size) alongside the GPU is essential to ensure the entire system is balanced for the intended workload and doesn't create unexpected bottlenecks.
The Rise of Alternative Hardware: Intel and AMD Challenge NVIDIA
While NVIDIA's CUDA ecosystem provides a powerful moat, viable alternatives are gaining traction, driven by intense demand and cost considerations:
- Intel Gaudi: Intel's Gaudi accelerators (especially Gaudi 2 and the newer Gaudi 3) are emerging as strong contenders, particularly demonstrating competitive price/performance for LLM training and inference. Benchmarks indicate Gaudi 3 can outperform even H100/H200 on specific models or scenarios (e.g., large output token inference), often at a lower proposed cost. Major players like IBM Cloud are now offering Gaudi 3 instances, supported by Intel's SynapseAI software stack and ecosystem partners. While SynapseAI is maturing and doesn't yet have CUDA's breadth, its performance on key AI workloads makes Gaudi a significant alternative to watch.
- AMD Instinct: AMD continues to push its Instinct accelerators (MI200 series, newer MI300 series) targeting HPC and AI. These GPUs boast large high-bandwidth memory capacities and strong theoretical performance. The supporting ROCm software ecosystem, while still less pervasive than CUDA, is steadily maturing and gaining adoption, particularly in research and HPC environments. Some cloud providers offer AMD instances, presenting a potential cost-saving alternative if the software stack aligns with user needs.
- Others: Niche architectures like Graphcore IPUs exist but remain less common in mainstream cloud offerings.
Key Takeaway: For maximum compatibility and access to the broadest software ecosystem in 2025, NVIDIA remains the default. However, evaluating Intel Gaudi and AMD Instinct for specific workloads, especially where price/performance is critical and software support exists, is increasingly prudent.
MLOps Platforms and Software Integration: Bridging the Gap
A major differentiator observed is the level of integrated ML tooling. Hyperscalers offer mature, comprehensive MLOps platforms (AWS SageMaker, Azure ML, Google Vertex AI) managing the entire lifecycle, significantly boosting team productivity but often creating vendor lock-in and adding cost. In contrast, many specialized GPU providers focus on delivering excellent infrastructure, expecting users to bring their own MLOps tools. This might involve offering basic pre-configured environments (common frameworks on Ubuntu), supporting container deployment (e.g., via NVIDIA NGC), or providing access via APIs.
This gap is increasingly filled by:
- Third-Party Cloud-Agnostic MLOps Platforms: Solutions like Domino Data Lab, Paperspace Gradient, and others can be layered on top of various infrastructure providers (e.g., the Vultr+Domino partnership).
- Provider-Specific Integrations/Tools: Some infrastructure providers offer lighter-weight tools – streamlined cluster management, inference APIs (like Lambda's or Nebius' AI Studio), or basic job orchestration.
- Integrated Stacks: Solutions like Apolo (in partnership with data centers) provide an MLOps platform directly coupled with managed infrastructure and value-added services.
Recommendation: For enterprises aiming for productivity and faster deployment, especially if lacking deep internal MLOps/DevOps expertise, leveraging an integrated software stack is highly valuable. When considering non-hyperscaler GPU providers, explicitly plan for an MLOps solution – whether a comprehensive third-party platform or a managed open-source toolkit (Kubeflow, MLflow). Failing to address the software layer can lead to significant engineering overhead, negating potential infrastructure cost savings. Ease-of-use and developer velocity often justify a higher platform cost if it accelerates model deployment and reduces operational burden.
Data Management and TCO Considerations: Beyond Compute Costs
Hidden costs and performance bottlenecks related to data management are critical technical considerations. Moving massive datasets required for AI training can incur substantial egress fees and network latency if data isn't co-located with compute. Best practices involve:
- Utilizing storage within the same cloud region/data center.
- Leveraging high-performance storage options offered by the provider (local NVMe, high-throughput shared file systems like VAST Data, Lustre, BeeGFS, Ceph, or optimized object storage).
- Considering the data pipeline's I/O capacity, can the storage system feed the GPUs fast enough, or will the GPUs sit idle, waiting for data?
When evaluating providers, scrutinize their storage architecture: Do they offer scalable, high-throughput options suitable for multi-node training? Are egress fees applicable, and under what conditions? A technically superior but inaccessible storage solution can cripple AI workload performance and inflate costs unexpectedly.
SLA, Reliability, and Multi-Cloud Strategies
While many providers advertise high reliability, often citing Tier III data centers, the specifics matter. Financially backed SLAs with meaningful credits for downtime are more common among larger, established providers. For AI workloads:
- Training: Often long-running; resilience via checkpointing can mitigate impacts of minor interruptions. However, frequent failures drastically reduce efficiency.
- Inference: Typically requires very high availability; even brief outages can disrupt production applications.
Many specialized providers may lack multi-region redundancy. Relying on a single data center introduces risk. Technical mitigation strategies include designing for multi-cloud or hybrid deployments, using containerization and infrastructure-as-code (Kubernetes, Terraform) to enable workload portability and failover. While adding complexity, this approach allows leveraging cost-effective specialized providers while hedging against outages or provider issues.
Security and Data Isolation
Data security and isolation are paramount, especially with sensitive datasets or proprietary models. Technically, providers use hypervisors or bare-metal provisioning to ensure tenant isolation at the compute level. Dedicated GPUs are standard practice, preventing direct sharing between tenants. For heightened requirements:
- Bare Metal: Offers maximum control and isolation.
- Software Isolation: Platforms like Apolo provide multi-tenancy controls within the software layer.
- Compliance: Verify provider certifications (SOC 2, ISO 27001, HIPAA, GDPR) relevant to your industry and data.
- Data Protection: Consider client-side data encryption or providers supporting advanced security features if needed.
These factors often favor established providers with proven compliance records or hybrid models where sensitive data remains on private infrastructure.
Navigating the Technical Trade-offs
The technical landscape for AI infrastructure presents a clear trade-off: integrated, feature-rich platforms from hyperscalers come at a premium cost and potential lock-in, while alternative specialized providers often offer significant cost savings but may require more internal technical expertise or reliance on third-party tools to manage the ecosystem (networking, storage, MLOps, security). A savvy approach often involves hybrid or multi-cloud strategies, selecting the optimal environment for each specific workload based on cost, performance, features, and compliance needs. Our deep dive confirms that substantial cost savings (potentially 30-50%) are achievable with careful planning, leveraging alternative GPU providers combined with robust MLOps practices, but this demands a thorough understanding and proactive management of the underlying technical complexities across the entire AI stack.
Pricing Analysis
GPU Pricing Models: Providers employ a range of pricing models for GPU compute. The most common is on-demand hourly pricing – a pay-as-you-go rate charged per GPU (or per instance) per hour, with no long-term commitment. All hyperscalers and many cloud providers use this model as the baseline. In addition, some providers offer discounted longer-term rentals or reserved instances – for instance, monthly or multi-month fixed rates. In our dataset, many providers simply calculated a monthly quote as hourly * 24 * 30 (essentially assuming full utilization). However, several indicated that deeper discounts are available for longer commitments (3 months, 6 months, 1 year). The bare-metal providers primarily operate on a monthly lease model – e.g., renting a dedicated server by the month instead of by the hour, which appeals to users with steady workloads.
Another model, used especially by marketplace platforms, is spot pricing or bidding for GPUs. Hyperscalers themselves also offer “spot” or preemptible instances at steep discounts (70–90% off) if the workload can be interrupted. While our RFP focused on stable capacity, this is worth noting. Some specialized providers have analogous community/spot models – for example, RunPod’s “community” instances allow users to run on GPUs contributed by others at a lower cost, with the caveat that the instance can be reclaimed by the owner (similar to preemptible behavior). These models add complexity to price comparisons.
Hidden Costs & Price Transparency: Data egress (network outbound) fees are a major hidden cost on many clouds. AWS, Azure, and Google all historically charged significant per-GB fees for outbound data (after a small free allowance). This can be an unpleasant surprise for AI teams sharing results or models with on-prem systems. The competitive response has been notable: Oracle Cloud includes 10 TB free outbound per month, and in response to customer and regulatory pressure, Azure and Google announced they will waive egress fees for customers who migrate off their cloud (underscoring the level of discontent around this practice). Many smaller providers simply forgo charging for reasonable levels of outbound data or charge at cost, making their pricing more predictable.
Another often-overlooked cost is support and premium services. In our survey, most specialized providers included standard support in their pricing, and some offered “white-glove” support as part of their value proposition. This means that the effective cost difference can be even greater if an enterprise would otherwise pay for high-tier support.
The next section will discuss some overarching trends, and then we will dive into the competitive analysis of individual providers, where we profile each surveyed provider in detail, comparing their offerings on the key dimensions identified.
Industry Trends
In addition to the structural market overview above, several emerging trends are notably shaping the GPU cloud and AI compute market’s trajectory:
Trend 1: Supply Constraints and Vertical Integration: The unprecedented demand for GPUs (especially NVIDIA’s high-end chips) led to supply shortages in 2023-2024. This dynamic is causing cloud providers to vertically integrate and secure supply. We expect to see more tie-ups between GPU manufacturers and cloud platforms, as well as potential acquisitions. Also, some providers are diversifying hardware – embracing AMD GPUs, Intel’s Gaudi series chips, or specialized AI chips – to alleviate reliance on NVIDIA’s constrained supply. AMD’s new MI300 GPUs, for instance, are touted to appear in some clouds. Intel has successfully launched its Tiber AI Cloud with Gaudi-based AI processors. If these alternatives prove cost-effective, they could shift the competitive balance by offering cost-effective or more available GPU capacity, though NVIDIA currently remains the gold standard for AI software compatibility.
Trend 2: Pricing Transparency and Value Beyond Compute: While the GPUaaS market exhibits intense price competition, a more fundamental challenge lies beneath the surface: the frequent disconnect between advertised GPU rates and the true Total Cost of Ownership. Many declarative pricing models lack transparency, obscuring significant costs associated with essential services like data storage, network egress, and support levels, leading to unpredictable expenses for customers. Addressing this requires significant pricing innovation across all provider segments. We are seeing initial steps in this direction, including more flexible commitment programs, the introduction of all-inclusive bundles for cost predictability, and a move towards reducing or eliminating punitive egress fees – partly spurred by customer demand and regulatory pressures. However, simply undercutting headline compute prices is an unsustainable strategy that risks a "race to the bottom." Long-term differentiation and market success will likely hinge not just on competitive pricing but on providers demonstrating clear value beyond raw compute. This necessitates ongoing innovation in transparent, predictable pricing models coupled with delivering value-added services, integrated platforms, or specialized support and services that genuinely justify the total investment for enterprise clients.
Trend 3: Strategic HPC Investment & Control Driven by AGI Horizons: Beyond current AI demands, the looming potential of Artificial General Intelligence (AGI), particularly Enterprise-coordinating AGI (ECAGI), is becoming a significant factor driving long-term infrastructure strategy. Enterprises recognize that harnessing such transformative capabilities will require substantial, sustained investment in powerful HPC infrastructure. Critically, the immense strategic value, potential risks, and sensitivity associated with AGI/ECAGI foster a strong enterprise need for greater control over the underlying compute, models, and data. This imperative drives a trend toward architecting AI capabilities within controlled environments, leading to increased investment in modernized on-premises data centers, private cloud deployments (often hosted within colocation facilities), and carefully managed hybrid cloud models where governance and security are paramount. While cloud technologies and partnerships will play a role, the emphasis is shifting towards infrastructure strategies (on-prem, private, colo) that guarantee enterprises the direct oversight and control necessary to develop and deploy future foundational AI technologies securely.
Trend 4: The Rise of Integrated Solutions: The GPUaaS market is rapidly maturing beyond simply offering access to raw compute power. Providing bare GPUs is proving insufficient, particularly for enterprise clients grappling with the complexities of AI development and often lacking deep internal MLOps expertise. Consequently, a significant trend is the emergence of providers offering turnkey, solution-oriented packages. This involves intelligently bundling essential MLOps platforms, pre-configured software frameworks (like PyTorch or TensorFlow environments), and vital human expertise – from managed services to hands-on AI consulting – directly alongside the GPU infrastructure. Smaller, specialized providers are increasingly differentiating themselves by delivering these integrated environments, effectively lowering the barrier to entry and accelerating time-to-value for customers. This contrasts with the traditional model of larger infrastructure players who typically rely on extensive partner networks or the customer's own team to bridge the gap between hardware and a functional AI workflow. Apolo exemplifies this shift, coupling its multi-tenant MLOps platform directly with hardware access and expert guidance. We anticipate this move "up the value stack" will continue, as providers compete not just on teraflops and price but on delivering complete, managed solutions. This strategy also fosters significant customer loyalty; when a provider's platform and services become deeply embedded in a client's operations, the relationship becomes far more resilient to purely price-based competition.
Trend 5: Data Locality & Sovereignty: Beyond performance and cost, the deployment of AI infrastructure is increasingly dictated by stringent Data Locality and Sovereignty Requirements. Driven by a growing patchwork of national and regional data privacy regulations (such as GDPR, CCPA, and others worldwide), industry-specific compliance demands, and rising geopolitical considerations, organizations face mounting pressure to control precisely where their sensitive data is processed and stored and which legal frameworks govern it. This represents a fundamental shift away from geographically agnostic cloud strategies. Enterprises, particularly those handling regulated or strategic data, now actively seek guarantees that their AI workloads will remain within designated jurisdictional boundaries. Consequently, this trend fuels demand for infrastructure providers who can offer verifiable data locality and sovereignty, boosts the prospects of regional players operating under specific legal umbrellas, and compels organizations to adopt hybrid or multi-provider strategies specifically designed to meet these critical compliance needs. The future direction points toward an AI infrastructure landscape increasingly shaped by data governance policies, where guarantees and control around data location become paramount factors in provider selection.
Trend 6: Potential Consolidation: The explosive growth in AI has triggered a gold rush in the GPUaaS and specialized AI infrastructure market, leading to a crowded landscape teeming with startups. While this signifies vibrant innovation, history suggests such fragmented markets are ripe for consolidation. We anticipate a multi-faceted shakeout: larger cloud providers may acquire niche players to quickly add specialized GPU capabilities or customer bases (as seen previously with deals like DigitalOcean's acquisition of Paperspace); major AI ecosystem players are actively acquiring technology to build end-to-end platforms; and traditional enterprise tech giants are also likely to acquire AI infrastructure startups to secure their relevance in this critical domain. Mergers between specialized providers seeking more significant scale and efficiency are also probable. While substantial venture capital continues to pour into select AI infrastructure companies, validating the market opportunity and creating several well-funded contenders, this level of investment likely cannot sustain the sheer number of current players indefinitely. Ultimately, as the market matures, differentiation will be paramount. Not all providers will survive long-term; those lacking a clear edge in technology, service model, niche focus, or operational scale may face acquisition, pivoting, or closure in the coming consolidation wave.
Trend 7: Multi-Cloud and Hybrid Strategies: Large AI users increasingly adopt a multi-cloud approach for GPUs, leveraging different providers for different needs to optimize cost and avoid vendor lock-in. For example, a company might use a more reliable computing source for baseline and production workloads but burst into a neo cloud or marketplace when it needs extra capacity economically. Tools for multi-cloud orchestration (Kubernetes, Terraform, etc.) make this easier. Additionally, hybrid deployments (a mix of on-prem GPUs and cloud GPUs) are common in industries like research and defense. Providers that facilitate hybrid connectivity (direct connect, VPN, etc.) or offer portable software stacks (so workloads can move between on-prem and cloud) have an edge.
Enterprise AI users increasingly reject a one-size-fits-all approach to AI infrastructure, instead strategically embracing multi-cloud and hybrid deployment models. This trend stems from a desire to optimize costs, mitigate vendor lock-in risks, enhance resilience, and ensure compliance with data governance policies. In practice, this means enterprises are selectively leveraging different GPUaaS providers – combining hyperscalers, specialized clouds, and regional players – to match the right environment to specific workload needs. For instance, stable production workloads might run on one provider, while cost-effective bursting for large training runs utilizes another. Furthermore, hybrid strategies, blending existing on-premises GPU investments with cloud resources, remain crucial, particularly in sectors like research or defense, or where data sensitivity dictates local processing. The rise of powerful orchestration tools and MLOps platforms simplifies managing resources across these diverse landscapes. Consequently, providers that facilitate this flexibility – through robust hybrid connectivity options (like direct connects), portable software stacks enabling workload mobility, and open APIs – are better positioned to meet the evolving, pragmatic needs of advanced AI users.
The next sections on the competitive landscape and provider profiles will shed light on both quantitative and qualitative differences (service, performance, etc.), which often explain why a given provider is more or less affordable.
Competitive Landscape
The competitive landscape for GPUaaS is diverse, spanning from tech giants to tiny startups. We categorize the players into several broad segments, as shown in Exhibit 2 and discussed below:
1. Specialized GPU Cloud Providers & Colocation: These are mid-sized cloud companies or startups focused primarily on GPU computing and AI workloads. Examples include Datacrunch, Vultr, Corvex.ai (ex. Klustr), and others. They usually offer virtual machine instances with GPUs (and sometimes containers or Kubernetes clusters) on their own infrastructure. Their scale is smaller than that of hyperscalers but still significant. Specialized providers often differentiate on price and flexibility: they tend to be 20-50% less expensive than hyperscalers for similar hardware and may offer niche features like a wider variety of GPU models. Some provide a simpler, developer-friendly experience. Support is also a point of differentiation: these companies usually have support teams knowledgeable in machine learning, offering more personalized help than one might get at a hyperscaler without a premium support plan. The trade-off is that specialized clouds might not have the massive service ecosystem – you won’t find managed databases or IoT services. Their focus is GPUs + the essentials around them (compute instances, storage, maybe some MLOps tooling). Uptime is generally good; many use rented space in Tier III data centers and claim ~99.5% - 99.9% availability, though they may not have the multi-region redundancy (some specialized players operate in a few regions rather than dozens). This segment is growing rapidly and overlaps with traditional colocation: data centers like Scott Data Center and iM HPC enable GPUaaS with built-in MLOps software and white-glove services within a traditional colocation model.
2. GPU Bare-Metal: This is a broad category of providers that offer dedicated physical servers with GPUs, often on a leasing model. They range from hosting companies that added GPU servers to their offerings (e.g., LeaderGPU) to startups born from crypto mining operations repurposed for AI (e.g., Genesis Cloud) to HPC-focused infrastructure firms (e.g., Voltage Park or Taiga Cloud). These providers typically don’t offer virtualized instances; instead, customers rent an entire server or cluster. For example, a provider might offer a server with 8× or 4×H100 GPUs, 2 CPUs, 512GB RAM, etc., for a monthly fee. The appeal of bare-metal is maximum performance (no virtualization overhead, exclusive access to the machine) and often deeper customization – clients can install their own software stack, use specific OS or drivers, and sometimes request custom networking setups. Pricing in this segment is often negotiated at monthly rates, sometimes lower on a per-GPU basis than on-demand clouds, especially if older GPU models are acceptable. However, setup might not be instantaneous (some require manual provisioning), and scaling up/down is less fluid than cloud instances. Many bare-metal providers operate out of a single or few data centers so that location choice can be limited. They often highlight technical specs: e.g., using Tier III or Tier IV facilities, providing InfiniBand networks for multi-node training, or housing in locales with more affordable electricity (i.e., Iceland) to pass on cost savings.
3. Marketplace & Decentralized Platforms: These platforms don’t (primarily) own hardware but aggregate supply from others – individual GPU owners or smaller data centers – and offer it to users. Examples: HydraHost, Cudo Compute, and to some extent, RunPod’s community section. They operate like an “Airbnb for GPUs”: providers list their machines (with specific GPUs) at chosen prices, and customers can choose based on price/performance/ratings. The marketplace handles the transaction, scheduling, and often packaging the environment in a container or VM for the user. The advantage is price – these platforms often have the lowest prices in the market because competition between independent hosts drives it down, and they may utilize otherwise idle hardware. The drawbacks are variability and trust: performance can vary from host to host; instances might disappear if a provider goes offline. Enterprises are generally wary of these platforms for anything mission-critical or involving sensitive data due to security concerns.
4. Other Emerging Models (Serverless ML, etc.): We also note providers that don’t fit neatly into the above, such as serverless ML platforms like Modal or Together.ai. These companies allow developers to run machine learning workloads without managing servers – for example, you write a function or container, and the platform runs it on GPUs behind the scenes, scaling as needed. They abstract the GPU infrastructure entirely. While not direct competitors for someone explicitly seeking to rent a GPU cluster, they do compete in the sense that a customer’s AI needs might be met via a serverless platform instead of renting raw GPUs. For instance, a team might choose Modal (which runs on cloud GPUs under the hood but charges per invocation or duration) to avoid dealing with infrastructure at all. These platforms often appeal to early-stage projects or applications (like serving an ML model via an API) where utilization is sporadic and cost is only incurred when work is done. They trade off fine-grained control for ease of use. Some of these emerging players have been included in our research to understand their approach, although pricing isn’t directly comparable (they typically don’t expose an hourly GPU price). Their presence underscores a trend of higher-level services built on top of GPU infrastructure. Similarly, initiatives like distributed volunteer compute (e.g., Together.ai’s project to train models on volunteer GPUs) show how unconventional models are developing at the fringes, though these are not significant for enterprises yet.
5. Hyperscalers: This group includes Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), and Oracle Cloud. These companies operate global-scale cloud infrastructure and offer GPUs as one service among hundreds. They cater to a broad market – from startups (often with free credits) to Fortune 500 enterprises – and emphasize full integration. For example, AWS offers deep integration of GPUs with its storage (S3), databases, and AI services (SageMaker for end-to-end ML). Azure similarly ties into Microsoft’s enterprise ecosystem and hybrid cloud offerings (like Azure Stack), and GCP leverages Google’s AI research pedigree (including unique offerings like TPUs, Tensor Processing Units). Hyperscalers generally run Tier III+ data centers worldwide and have 99.9–99.99% SLAs, benefiting from highly redundant networks and multi-zone architectures. Their differentiators are scale, reliability, and a one-stop-shop breadth of services. However, as noted in pricing, they tend to be premium-priced and have complex cost structures. They also often require technical expertise to optimize: the platforms are powerful but complex. All major hyperscalers have invested heavily in AI-specific partnerships (e.g., Azure’s close collaboration with OpenAI, Oracle hosting NVIDIA’s DGX Cloud), indicating how strategic GPU services are for them.
Competitive Analysis (Provider Profiles)
In this section, we present a structured profile of the providers surveyed in our research, covering their business model, pricing for the requested H100 cluster, infrastructure (data centers, SLA), services, and other observations. Providers are grouped by category for clarity.
Please note that the list of providers included in this section is mainly limited to those who presented an offer that met the specific requirements of our research: reserved 2x DGX/HGX H100 servers (with 16 total GPUs), 20TB of NAS storage, and 30TB of monthly data egress for a contract term of 6-12 months.
Specialized GPU Cloud Providers
Lambda Labs
Website: https://lambdalabs.com/
Company Overview :
Lambda Labs positions itself as a specialized AI compute cloud that focuses on providing high-performance GPU resources tailored specifically for ML engineers and AI researchers.
Sales Process:
Our team encountered challenges with direct Lambda interaction; two attempts to contact Lambda's sales team via their website form for an initial quote request did not yield a response. This suggests potential difficulties or delays when pursuing custom configurations, enterprise agreements, or initial inquiries outside the self-service path. Lambda heavily promotes a self-service model for its GPU Cloud, enabling users to "Create a cloud account instantly" and spin up GPU instances and even clusters without mandatory sales engagement.
Data Centers:
Lambda Labs states that its infrastructure is primarily located within the United States. For its colocation services, it publicly claims to utilize a Tier III data center facility. However, specific public details regarding the exact locations, number of data centers supporting their GPU Cloud product, or independent verification of Tier III certifications for all cloud locations were not readily available from public sources or their website. Given the lack of response from their sales team, our research team could not verify these details directly.
SLA & Uptime:
Specific SLAs or guaranteed uptime percentages for the Lambda GPU Cloud product are not publicly disclosed on their website or in readily available documentation. While the claimed use of Tier III infrastructure implies a focus on reliability, formal commitments regarding uptime, performance guarantees, or support response times appear to be subject to negotiation within enterprise contracts rather than standardized public offerings. This research could not obtain specifics due to the previously mentioned lack of sales engagement.
Additional Services/Software:
Lambda Labs primarily focuses on hardware, but its cloud platform provides some ease-of-use enhancements, including the deployment of instances via a web console or API. Lambda does not offer an integrated, end-to-end MLOps platform. Although the platform is designed to accommodate these external tools, users are expected to bring their own tools for experiment tracking, model registry, workflow orchestration, and advanced deployment/monitoring. They provide a dedicated Inference API designed as an OpenAI-compatible, potentially serverless way to utilize LLMs.
Specifications:
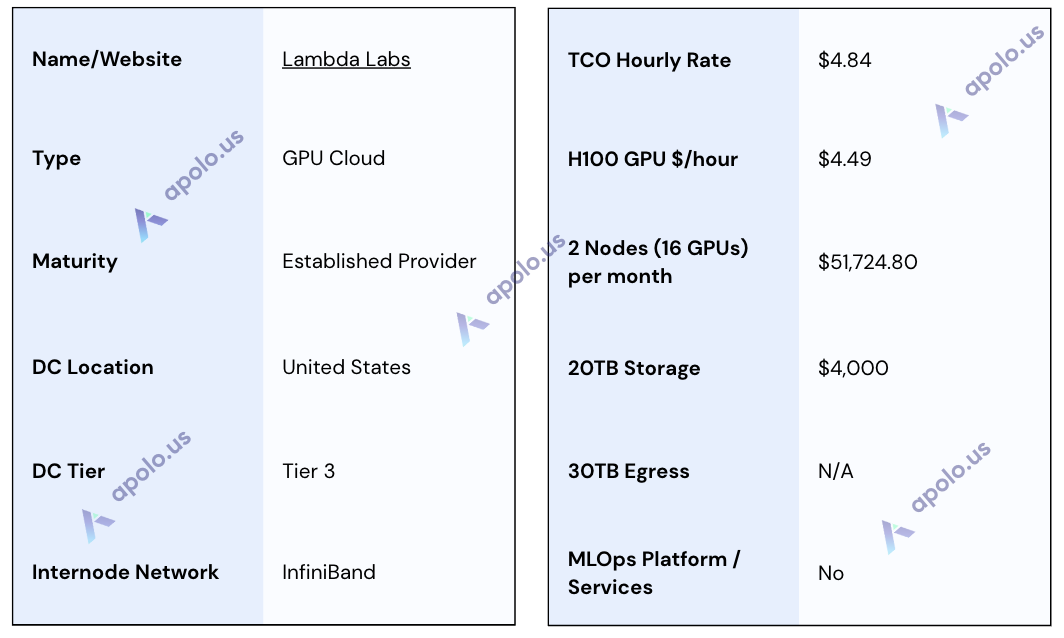
Total Cost of Ownership (TCO) Note: While the hourly GPU rate is clear, the full TCO requires factoring in storage costs.
Vultr
Website: https://www.vultr.com
Company Overview:
Vultr is a large, independent global cloud infrastructure provider (IaaS) that offers a wide portfolio of services, including compute, bare metal, and increasingly GPU solutions, targeted at AI/ML workloads for a diverse customer base from startups to enterprises.
Sales Process:
Vultr offers both self-service provisioning through its platform and a direct sales engagement model. Based on our research team interaction, Vultr's sales process was notably responsive: contact initiated via their website resulted in quickly scheduled meetings, a formal offer was provided in a timely manner, and the sales team followed up proactively regarding the next steps.
Data Center:
Vultr operates an extensive global network with 32 data center locations advertised across multiple continents. While facilities are built for high availability with redundancy and standard compliance features, specific Tier ratings (Tier IV and III) are not uniformly substantiated across all public documentation for these locations.
SLA & Uptime:
Vultr publicly offers a 100% Uptime SLA covering Network and Host Node availability. This guarantee is backed by a tiered service credit system that is applicable if documented downtime exceeds specific thresholds, providing financial recourse for service disruptions.
Additional Services/Software:
Vultr enhances its GPU compute offerings via partnerships and specific services. For users needing comprehensive ML lifecycle management, it offers a validated solution integrating Domino Data Lab's MLOps platform. Vultr also provides "Vultr Serverless Inference" for the simplified deployment of GenAI models. While high-speed networking connects clusters, the platform generally accommodates users bringing their own preferred tools for aspects beyond these specific integrations.
Specifications:
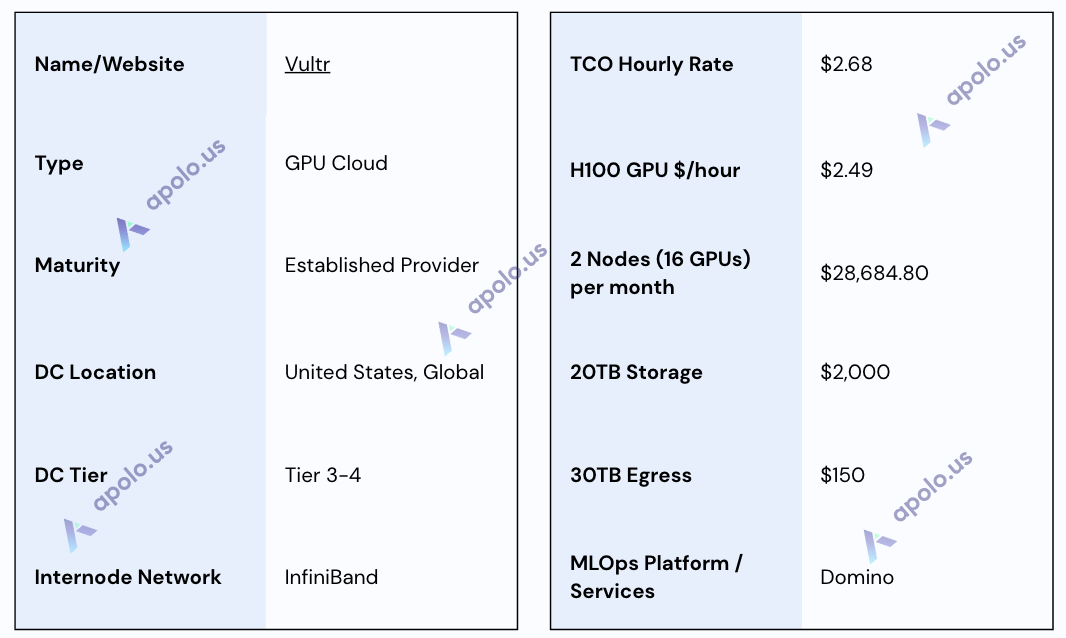
TCO Note: The effective hourly rate includes estimated costs for the specified storage and egress based on the quote received.
Nebius
Name: Nebius
Website: https://nebius.com/
Company Overview:
Nebius emerged in 2024 as an independent international entity retaining AI and cloud assets following a separation from Yandex. It focuses on providing full-stack GPUaaS and AI platform solutions designed to support the entire AI development lifecycle for enterprise clients.
Sales Process:
Nebius employs a direct sales model supplemented by a self-service option. Our research interaction found the sales team to be responsive, providing fast turnarounds, demonstrating good engagement, and offering a Proof of Concept credits grant.
Data Centers:
Nebius operates globally with live locations including Paris, France (colocation) and Keflavik, Iceland (colocation using 100% renewable energy with partner Verne). Upcoming US locations include Kansas City, MO (Q1 2025 target) and New Jersey (Phase 1 Summer 2025 target), indicating significant expansion plans. Infrastructure is considered Tier III+ with redundancy.
SLA & Uptime:
Nebius provides specific uptime guarantees detailed in its SLA, varying by service: 99.98% for Object Storage, 99.90% for Managed Kubernetes, and 95.00% for standalone applications. These SLAs are supported by their Tier III+ claimed infrastructure and include service credit provisions for downtime exceeding thresholds.
Additional Services/Software:
Nebius offers a suite of services beyond GPU provisioning: "AI Studio" for fine-tuning and inferencing open-source models, Managed Kubernetes and Slurm-based clusters, and managed services for tools like MLflow, PostgreSQL, and Spark. Infrastructure management uses standard cloud-native tools (Terraform, API, CLI, Console). Confirmed use of high-speed InfiniBand networking (400Gbps).
Specifications:
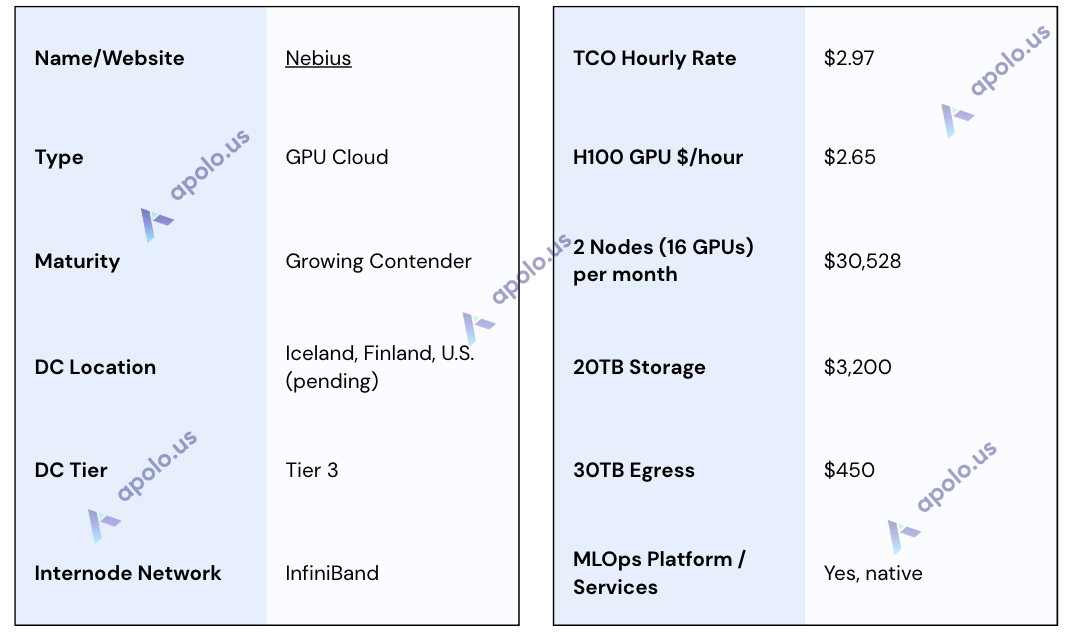
DataCrunch
Website: https://datacrunch.io/
Company Overview:
DataCrunch is a European cloud service provider (founded 2020, HQ in Helsinki, Finland) specializing in GPUaaS solutions optimized for AI/ML workloads, emphasizing sustainability through renewable energy-powered data centers.
Sales Process:
This research experienced DataCrunch's sales process as notably positive, one of the best among all participants. It was characterized by knowledgeable, professional interactions and a thorough engagement that resulted in a detailed offer. This suggests a strong, consultative approach for potential clients.
Data Centers:
DataCrunch operates infrastructure in Nordic data centers (Finland, Iceland) known for utilizing 100% renewable energy sources. These facilities are rated as Tier 3 and Tier 2, are ISO 27001:2022 certified, and operate under GDPR compliance, ensuring EU data storage.
SLA & Uptime:
The infrastructure resides in ISO 27001-certified data centers, indicating a focus on security and operational standards. DataCrunch provides 24/7 support via chat and email, with dedicated account managers and ML/AI team support also available. It offers a 99.9% uptime guarantee on the GPU level.
Additional Services/Software:
DataCrunch focuses on high-performance infrastructure, offering bare-metal access and custom clusters featuring NVIDIA H100 SXM5 80GB GPUs and InfiniBand networking (up to 800 gbit for clusters). They provide "Serverless Containers" for inference workloads and a "Dynamic Pricing" option for compute. While DataCrunch offers ML/AI team support and pre-installs necessary drivers, it does not provide an integrated MLOps platform, allowing users flexibility to bring their own tools.
Specifications:

TCO Note: A major TCO advantage is the unmetered traffic / no egress fees on standard connections. DataCrunch also offers Dynamic Pricing (from $1.95/hr H100 but variable) and discounted long-term contract rates (e.g., $1.64/hr H100 2-year contract).
Fluid Stack
Website: https://www.fluidstack.io
Company Overview:
Fluidstack is an AI cloud provider that delivers large-scale, high-performance GPU clusters (currently focusing on NVIDIA H100) primarily through a Private Cloud model serving leading AI labs and enterprises.
Sales Process:
The sales engagement during this research was positive, with a fast turnaround. An offer was provided by Day 2. Communication highlighted significant flexibility in structuring deals, offering both reserved clusters (8+ GPUs, 30+ days minimum) and on-demand API access with per-minute billing and no minimums. The detailed proposals provided indicate a responsive and capable sales/solutions team geared toward large, custom AI infrastructure needs.
Data Centers:
Fluidstack operates infrastructure primarily in a Texas, US data center, rated as Tier 3. Compliance includes GDPR, with ISO 27001, HIPAA, and SOC 2 Type II reportedly in progress.
SLA & Uptime:
Fluidstack guarantees a 99.5% uptime SLA for both the compute nodes and the InfiniBand networking fabric within its clusters. Support is available 24/7 via Slack, with a stated 15-minute response time commitment and a dedicated account manager.
Additional Services/Software:
Fluidstack focuses on delivering optimized hardware clusters featuring NVIDIA H100 SXM5 GPUs interconnected with high-performance InfiniBand NDR networking. They offer high-performance VAST Data shared storage. They provide optional managed Slurm or Kubernetes for orchestration and grant access to monitoring tools (Prometheus/Grafana). MLOps support/consulting is not included.
Specifications:
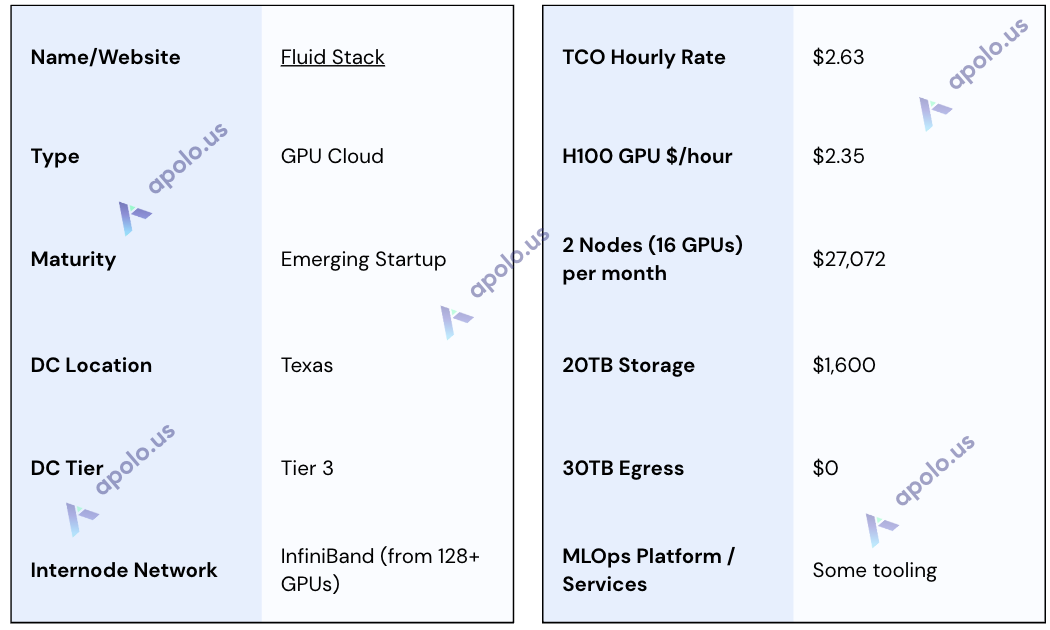
TCO Note: The effective hourly rate includes the quoted object storage cost ($80/TB/month). A significant TCO advantage is the stated no charge for data ingress/egress. Fluidstack offers multiple pricing tiers based on commitment length (1, 3, 6, 12, 24, 36 months available per PDFs), providing lower hourly rates (e.g., $2.15/hr for 6 months). Payment is typically monthly in advance.
Crusoe
Website: https://crusoe.ai/
Company Overview:
Crusoe provides high-performance GPU cloud infrastructure (primarily NVIDIA H100 SXM) for AI workloads. It is a vertically integrated AI infrastructure provider known for its innovative approaches to powering data centers using stranded or clean energy sources.
Sales Process:
The sales engagement during this research was characterized by quick responses to inquiries and flexibility in communication. Crusoe provided detailed responses via documentation and specific pricing quotes, indicating a responsive process capable of handling enterprise requirements. They also expressed willingness to share further technical details under NDA.
Data Centers:
Crusoe operates data centers in locations including Iceland and the US (Houston, TX confirmed), often leveraging their unique energy sourcing model. Specific Tier ratings are not publicly detailed, but facilities are designed for demanding AI workloads. Crusoe is SOC 2 and GDPR compliant; however, HIPAA compliance was not available at the time of inquiry but was under review.
SLA & Uptime:
While Crusoe highlights reliability features like robust monitoring and automatic node-swapping, a specific, publicly guaranteed uptime percentage (SLA) was provided at 99.5% level with credits compensation for the downtime. 24/7 enterprise support is included with services.
Additional Services/Software:
Crusoe offers compute primarily on H100 SXM 80GB nodes configured with high-speed RDMA InfiniBand networking. Nodes include significant local NVMe storage. Recently, Crusoe launched managed services, including Crusoe Managed Inference (API-based model serving) and Crusoe AutoClusters (fault-tolerant orchestration for Slurm and Kubernetes), reducing the operational burden for users. Direct ML/AI engineering consulting support was noted as not applicable in the RFP response.
Specifications:
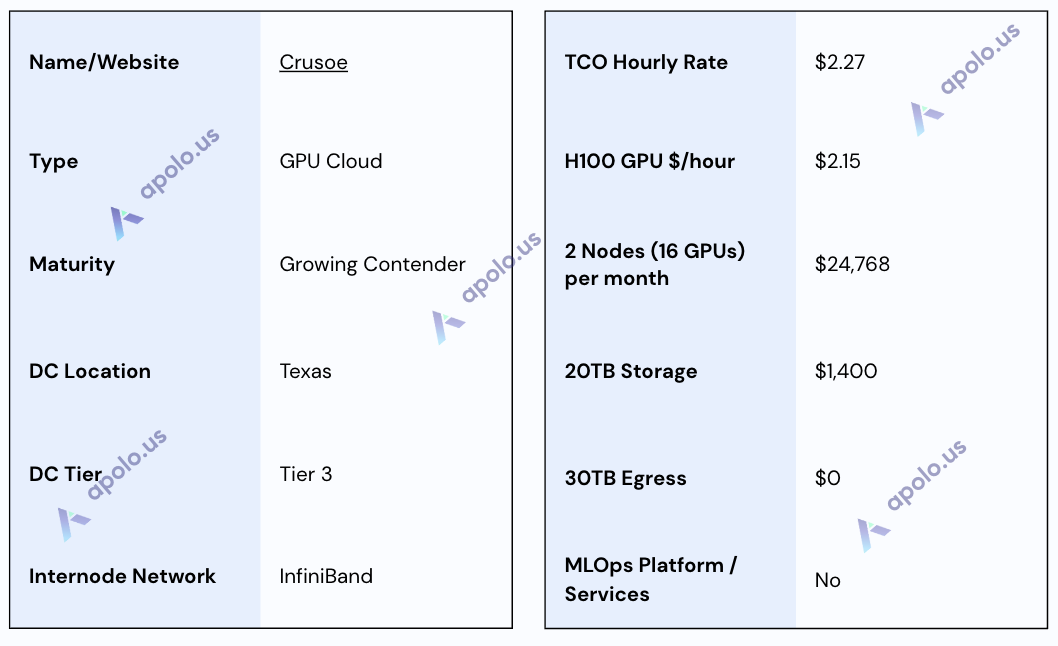
TCO Note: The effective rate reflects the competitive 12-month reserved pricing for compute. Significant local NVMe storage is included per node; Reserved instance contracts require a 25% upfront payment. Enterprise support is included. Tiered pricing is available for different regions and commitment lengths (6, 12, and 24 months).
Scaleway
Website: https://www.scaleway.com/
Company Overview:
Scaleway, part of the Iliad Group, is a European full-stack cloud provider that focuses on AI infrastructure and GPUaaS. As an NVIDIA Cloud Partner, it operates with significant H100 capacity (including SuperPODs and clusters) and serves major European AI players. Scaleway emphasizes EU data sovereignty, is ISO 27001 certified, and is GDPR compliant.
Sales Process:
This research found Scaleway's sales process to be very effective, marked by fast turnarounds, professional interactions, and high-quality marketing collateral. The detailed response provided to the RFP and informative email communications demonstrate a sales and solutions team well-equipped to handle complex AI infrastructure requirements. We had two sales calls and a platform demo and have received a structured RFP response.
Data Centers:
Scaleway operates primarily from data centers in Paris, Amsterdam, and Warsaw, ensuring European data residency. Facilities like DC5 are highlighted for energy efficiency (e.g., adiabatic cooling). The infrastructure supporting the quoted GPU clusters is stated to meet Tier 3 standards. The data centers are ISO 27001 certified and GDPR compliant.
SLA & Uptime:
Scaleway provides a specific 99.5% node uptime SLA for the quoted GPU cluster hardware. This guarantee is supported by its Tier 3 infrastructure. Compensation mechanisms for downtime exceeding this threshold are noted as subject to discussion or specific contract terms.
Additional Services/Software:
Scaleway complements its GPU offerings with a broader cloud ecosystem. High-performance clusters utilize InfiniBand or Spectrum-X networking. Environments can be pre-configured with SLURM, Ubuntu, and CUDA. Platform services include Managed Kubernetes and Serverless Functions. While lacking a native integrated MLOps suite, solutions like Craft MLOps are available via their Marketplace. Monitoring beyond basic hardware checks (nvidia-smi) is the customer's responsibility. Support includes 24/7 tickets and optional Slack/TAM channels.
Specifications:
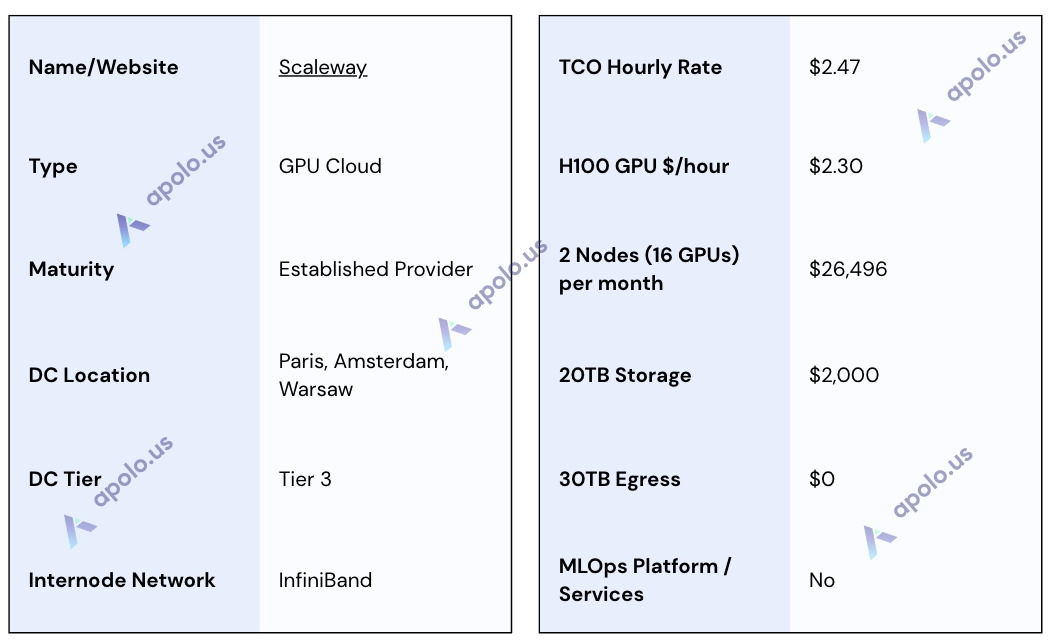
TCO Note: The effective hourly rate includes estimated costs for high-performance storage. Payment is typically monthly in advance, with long-term discounts negotiable.
Scott Data
Website: https://www.scottdatacenter.com/
Company Overview:
Scott Data is a Tier III multi-tenant data center in Omaha, Nebraska. Traditionally providing colocation services, SD has strategically expanded into offering GPUaaS to meet the growing demand for high-performance computing resources for AI/ML workloads. This move aligns with their broader strategy of delivering cutting-edge infrastructure services that support advanced computational demands.
Sales Process:
Scott Data is noted for a highly customer-oriented and individual approach. The sales process is consultative, likely involving close collaboration to understand specific AI requirements and tailor a solution encompassing Scott Data's infrastructure bundled with the Apolo platform and relevant managed services.
Data Centers:
The primary facility is a 110,000 sq ft Tier III certified data center in Omaha, NE, designed for high availability and security. It features redundant power, cooling, and networking, along with robust physical security measures appropriate for enterprise and mission-critical workloads. The facility is SOC 2 and ISO 27001 compliant.
SLA & Uptime:
Leveraging its Tier III-certified infrastructure and operational best practices, Scott Data provides a foundation for high availability and reliability. While specific uptime percentage guarantees are not publicly detailed, the infrastructure design and operational focus aim to minimize downtime for critical AI workloads. Formal SLA commitments are established on an individual basis within customer contracts.
Additional Services/Software:
One of Scott Data's key differentiators is the seamless integration of the Apolo MLOps platform into its GPU infrastructure, which provides a full-stack environment for managing the entire AI lifecycle. Crucially, Scott Data offers comprehensive managed services that extend beyond basic support to include specialized MLOps support and AI consulting expertise, including access to data scientists and ML researchers. High-performance storage solutions are available, supported by high-quality data center networking, including inter-node Spectrum-X connection.
Specifications:
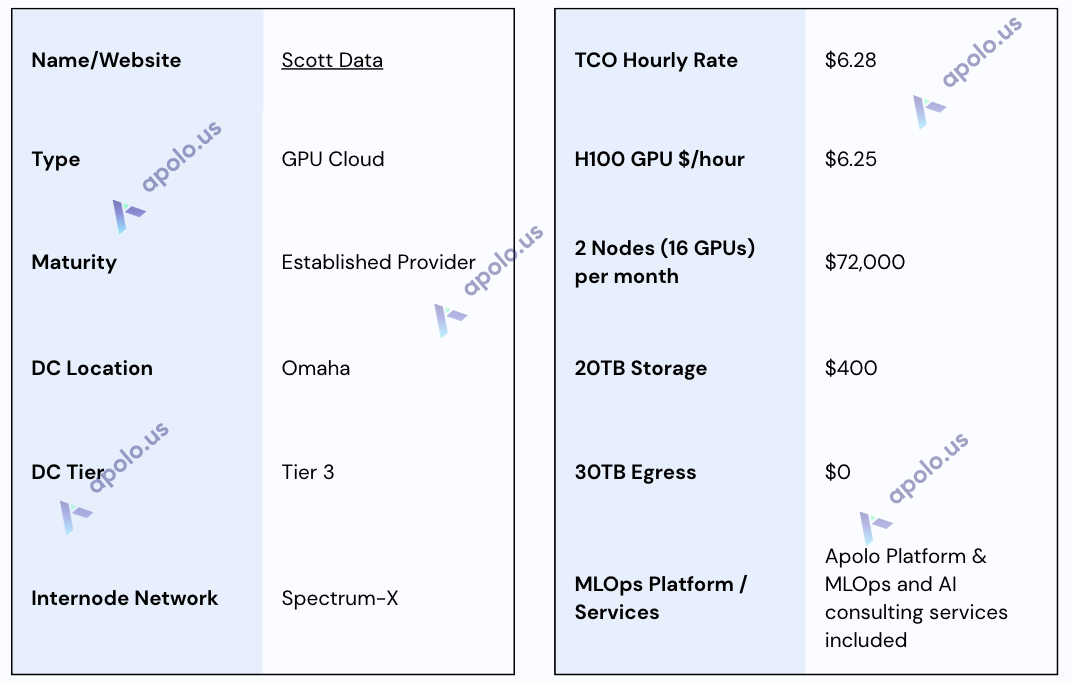
TCO Note: The pricing reflects figures obtained during research and represents a bundled package including infrastructure, the integrated Apolo MLOps platform, and potentially managed MLOps/AI support services.
Special “Start Your Engines” Package: Scott Data's 90-day “Start Your Engines" package offers businesses an easy and affordable way to test the power of AI. For a fixed cost of $9,000 for 90 days, this turnkey solution includes not only the necessary technology (H100 GPU hours, storage, and data transfer) but also access to data scientists and MLOps/DevOps support. It's designed as a low-risk entry point for companies looking to explore practical AI use cases and understand how AI can benefit their operations without hidden costs.
Coreweave
Our research team contacted CoreWeave via their website inquiry form. The initial response was prompt, and CoreWeave was positioned as the "AI Hyperscaler. " They highlighted their work with leading AI companies and directed us to schedule a call with a senior team lead.
During the subsequent sales call, it became apparent that CoreWeave primarily focuses on large-scale deployments for reserved capacity, starting at 100+ GPUs. Our requirement for a smaller reserved cluster (initially discussed as two nodes / 16 GPUs) did not align with their standard reserved offerings. CoreWeave suggested exploring their on-demand options or potentially working through one of their partners, introducing us to a contact at Andromeda for further discussion. After reviewing our specific RFP requesting 16 GPUs, Andromeda confirmed that the scale and duration of our requirement were not a suitable fit for their direct engagement model, and they declined to proceed, wishing us luck in finding compute elsewhere.
GPU Clouds Comparison
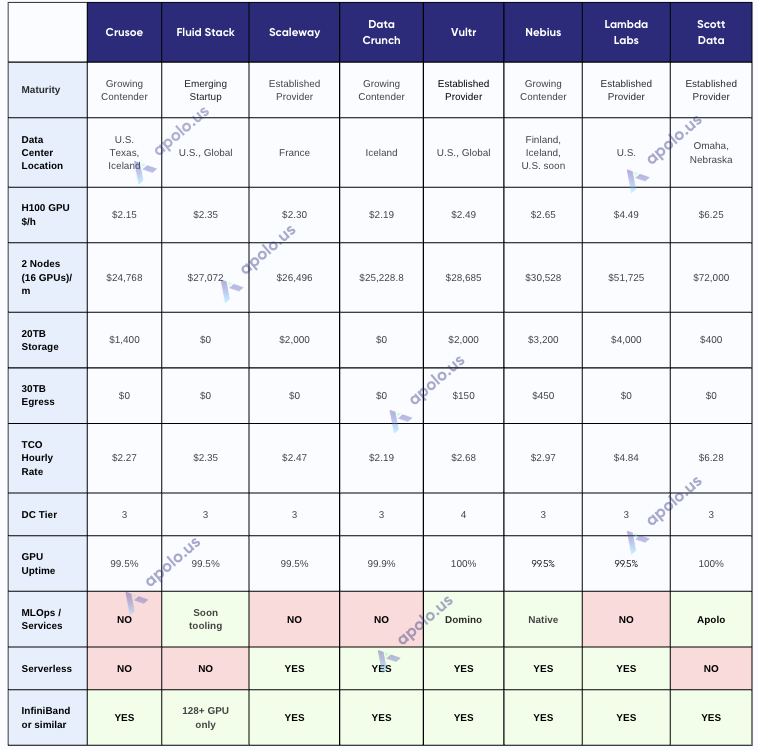
GPU Bare-Metal Providers
Voltage Park
Website: https://www.voltagepark.com/
Company Overview:
Voltage Park provides bare-metal access to large-scale NVIDIA HGX H100 GPU clusters (utilizing Dell PowerEdge servers), positioning itself as an accessible and affordable AI cloud alternative. Funded significantly by private and non-profit capital and owning its hardware, it acquired the TensorDock marketplace in early 2025 to broaden its reach.
Sales Process:
Our research interaction confirmed Voltage Park's reputation for a quick and responsive sales process, with a detailed offer provided by the next business day. This aligns with their stated focus on rapid deployment and accessibility. The sales team appears capable of handling detailed technical requirements efficiently.
Data Centers:
Voltage Park operates six data center locations in four US states (WA, UT, TX, VA), explicitly claiming Tier 3+ design standards for these facilities. The locations are chosen strategically in low-cost states near major network peering points.
SLA & Uptime:
Voltage Park provides a Node SLA, guaranteeing ≥ 99.5% monthly uptime for single nodes, backed by a financial credit structure. They offer 24/7 global support from both their own team and Dell for the underlying hardware, supporting the reliability implied by their Tier 3+ infrastructure.
Additional Services/Software:
The core offering is bare-metal access to HGX H100 nodes (Dell PowerEdge XE9680 servers with Intel Xeon CPUs and 1TB+ RAM). Networking includes redundant 100 Gbps internet connectivity and high-performance InfiniBand with NVIDIA SHARP support. VAST Data storage (NFS/Object) is offered, with up to 40TB included for free. While no integrated MLOps software platform is provided (users bring their own stack), Voltage Park offers expert support with knowledge of Slurm, Kubernetes, and other relevant technologies to assist users in managing the bare-metal environment. Monitoring tools are also available.
Specifications:
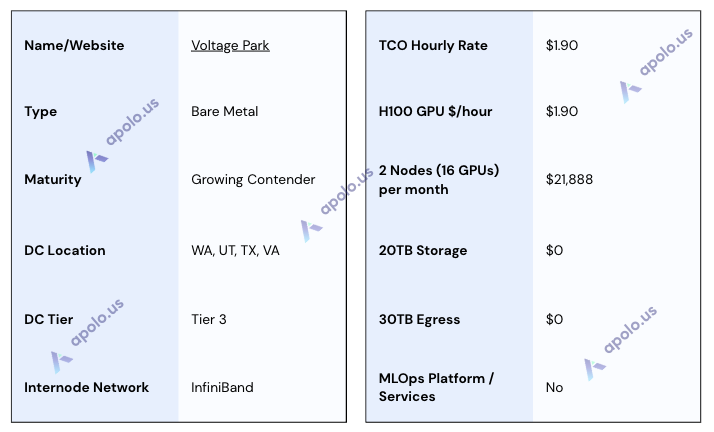
TCO Note: Voltage Park's pricing is highly competitive due to significant inclusions. The quoted rates include up to 40TB of storage and all ingress/egress traffic at no additional cost. Also included are a free failover node, a dedicated internet port, support, and a trial node. This bundled approach dramatically simplifies TCO calculations and offers substantial potential savings.
Massed Compute
Website: https://massedcompute.com/
Company Overview:
Massed Compute provides high-performance cloud GPU infrastructure, offering bare-metal access primarily focused on NVIDIA GPUs (like the H100).
Sales Process:
This research found that Massed Compute offered a positive and technically proficient sales engagement. Interactions were characterized by technically in-depth meeting and relatively quick delivery of a detailed offer.
Data Centers:
Massed Compute operates three data centers located in the US Midwest, all rated as Tier 3 facilities. They mention adhering to common compliance standards (like ISO 27001, SOC 2, HIPAA, GDPR).
SLA & Uptime:
Infrastructure resides within confirmed Tier 3 data centers, suggesting a design focused on reliability. Massed Compute includes expert engineering support as part of their offering. The specific uptime percentage guarantee was detailed as 99.9%, with credit compensation for downtime.
Additional Services/Software:
Massed Compute offers bare-metal and virtual machine instances featuring high-end hardware (e.g., H100 GPUs, Intel Xeon CPUs, and large RAM/NVMe configurations). Networking includes standard Ethernet and IP over InfiniBand (IPoIB) capabilities for private interconnects. A key offering is included expert NVIDIA GPU engineering support accessible via Slack. While they can pre-install necessary software (drivers, CUDA, Docker, etc.), they do not provide an integrated MLOps platform, focusing instead on robust infrastructure coupled with expert support. They also offer free benchmarking services and potentially user-friendly VDI/API access.
Specifications:

TCO Note: Massed Compute offers a simple, highly competitive pricing structure. The effective rate includes the extremely low storage cost ($0.03/GB/month). A major TCO advantage is that there is no charge for ingress or egress, combined with expert engineering support. Tiered discounts are available for longer commitments (down to $1.79/hr for 18 months).
Corvex.ai (ex-Klustr)
Website: https://www.corvex.ai/
Company Overview:
Corvex.ai (which operated as Klustr.ai at the time of initial research) provides specialized, high-performance bare-metal GPU cloud infrastructure. It currently focuses on NVIDIA H200 resources tailored for demanding AI/ML and HPC workloads.
Sales Process:
Corvex utilizes a direct, consultative sales engagement model. Our research involved direct communication yielding specific availability details (e.g., 2 nodes/16 H200 GPUs in US East), infrastructure specifications (Tier III+ DC), and clear pricing for various lease terms. They outlined available durations, explicitly noting no 6-12 month options but offering flexible weekly/monthly rollovers alongside 2 and 3-year leases. Pricing examples included different rates for monthly vs. multi-year commitments, potentially involving prepayment based on credit.
Data Centers:
Corvex utilizes US-based data center infrastructure, with specific availability confirmed during this research within a US East facility claiming Tier III+ standards (per sales communication). A key feature highlighted across their offering is the use of non-blocking NVIDIA Quantum-2 InfiniBand networking for high-speed, low-latency inter-node communication crucial for distributed AI workloads.
SLA & Uptime:
Corvex states they provide 24x7x365 responsive support with SLAs, including an Uptime SLA backed by proactive maintenance and monitoring. While an SLA framework exists, specific guaranteed uptime percentages were not detailed in public documentation or their offering.
Additional Services/Software:
Corvex focuses on delivering high-performance bare-metal access to H200 GPU servers, giving customers direct control over the hardware. The integration of high-speed InfiniBand networking is a core part of their offering, designed to optimize distributed training performance. Corvex does not provide an integrated MLOps software platform; customers are expected to bring their own software stack, tools, and orchestration layers.
Specifications:
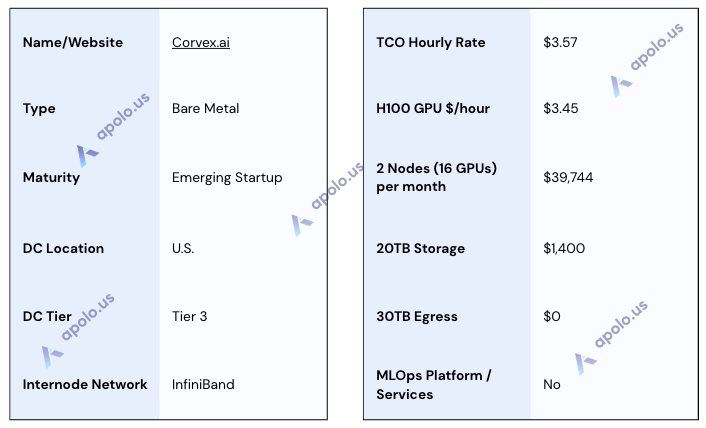
TCO Note: The effective hourly rates include the quoted storage cost ($0.07/GB/month). 2-Year pricing involved a prepayment requirement.
Taiga Cloud
Website: https://taigacloud.com/
Company Overview:
Taiga Cloud operates as the Generative AI cloud platform of Northern Data Group, positioned as Europe's largest GPUaaS provider. They focus on delivering large-scale, high-performance bare-metal GPU clusters (primarily NVIDIA H100 and newer generations) built with partners and powered by renewable energy, targeting AI labs and enterprises requiring data sovereignty within Europe.
Sales Process:
The engagement during this research was positive. It featured a good meeting with a technically in-depth discussion, a quick sales response, and a platform demonstration.
Data Centers:
Taiga Cloud operates data centers within Europe, with specific locations mentioned including Sweden, Norway, England, and Portugal. The facilities leverage renewable energy sources. Data Center Tier rating is stated to be dependent on the specific location. The parent company, Northern Data Group, holds ISO 27001 certification, implying strong security practices, and operations are inherently focused on GDPR compliance, given the EU footprint.
SLA & Uptime:
Taiga Cloud commits to a 4-hour support response time 24/7 for issues. The SLA guarantees up to 99.7% node availability, depending on the data center. Service credits will be issued for downtime, and redundancy options are available based on the data center.
Additional Services/Software:
Taiga Cloud focuses on providing bare-metal HGX H100 nodes featuring high-end components like Intel Xeon CPUs, large RAM configurations, local NVMe for OS, and NVIDIA BlueField-2 DPUs. Clusters utilize high-speed InfiniBand networking. High-performance NFS shared storage (up to 2PB) leveraging VAST Data technology is available. Taiga Cloud explicitly does not provide an integrated MLOps platform; they offer base OS (Ubuntu) with drivers/CUDA/Docker, supporting custom images, but users must bring their own MLOps tools. Monitoring capabilities via their portal are limited, with users responsible for detailed performance tracking.
Specifications:
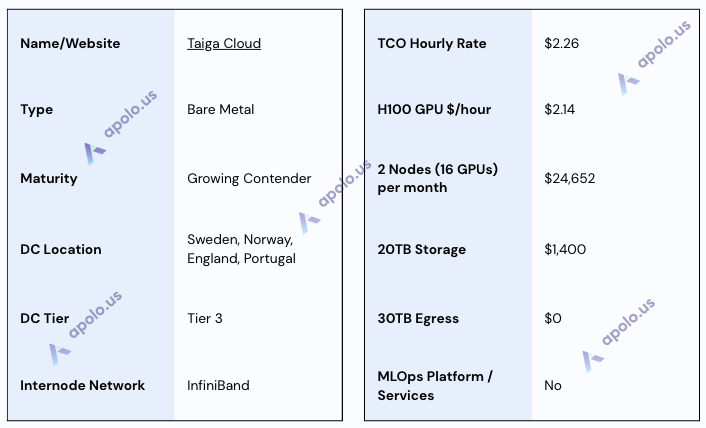
Oblivus
Website: https://oblivus.com/
Company Overview:
Oblivus provides high-performance GPU cloud infrastructure, offering bare-metal access to NVIDIA GPU resources (like H100 SXM5 via Dell servers). They focus on serving AI/ML and other compute-intensive workloads from US-based data centers and emphasize affordability, flexibility, and efficient operations.
Sales Process:
The sales engagement highlighted a quick response time and flexibility. Oblivus provided a detailed response to the RFP and offered a test period on the exact nodes proposed before commitment. They were willing to accommodate custom software installation requests, indicating a capable and adaptable sales process.
Data Centers:
The infrastructure offered during this research is located in a single-tenant data center rated Tier 3 in Texas, US.
SLA & Uptime:
Oblivus didn’t mention any SLA and uptime guarantees in the offering.
Additional Services/Software:
Oblivus delivers bare-metal Dell PowerEdge servers equipped with H100 SXM5 GPUs, large local NVMe storage (~30TB included), and high-speed 3200Gbps InfiniBand internal networking. They can pre-install required software (OS, drivers, frameworks) and offer ML/AI engineer support/consulting. Notably, no built-in shared NAS or Object Storage solutions were available at the offered location. While no integrated MLOps platform is mentioned, they may offer an "OblivusAI OS" with relevant libraries.
Specifications:

TCO Note: The pricing is highly competitive, primarily driven by the compute cost as significant local NVMe storage (~30TB per node) is included and, crucially, ingress and egress are completely free. Reserved contracts require an upfront payment (20-25%).
LeaderGPU
Website: https://www.leadergpu.com/
Company Overview:
LeaderGPU is a dedicated server provider based in Europe, offering hosting solutions including high-end NVIDIA GPU configurations.
Sales Process:
The sales interaction during this research required initial clarification regarding specific GPU needs. While providing links to available server configurations and pricing, the response was noted as potentially delayed compared to other providers and did not include a full response to the structured RFP document. Communication highlighted very limited availability for the requested H100 configuration, suggesting potential inventory constraints or a focus on specific pre-configured server rentals.
Data Centers:
LeaderGPU operates from data centers located within Europe. Specific public details regarding exact locations, Tier ratings, or compliance certifications (e.g., ISO 27001, SOC 2, GDPR) were not provided.
SLA & Uptime:
No specific uptime percentage guarantees or details of a formal Service Level Agreement (SLA) for LeaderGPU services were provided.
Additional Services/Software:
The service is oriented towards users needing bare-metal access who manage their own software stack beyond the provided OS (Ubuntu options available); no integrated MLOps platform or extensive managed services were identified.
Specifications:
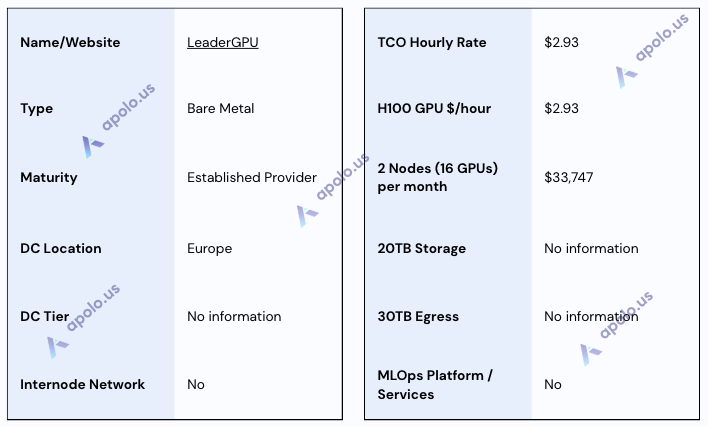
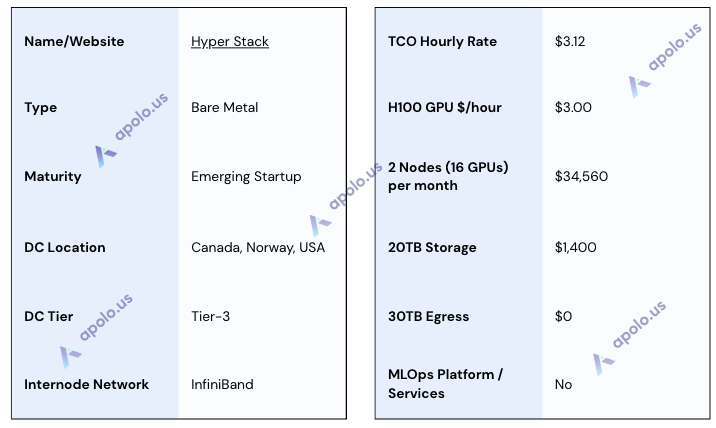
Hyperstack
Website: https://www.hyperstack.cloud/
Company Overview:
Hyperstack, part of NexGen Cloud, is a GPU-as-a-Service platform that provides self-service access to NVIDIA GPU infrastructure. It offers a range of GPU types, including large "Supercloud" clusters based on the NVIDIA DGX reference architecture, targeting AI/ML, deep learning, and other compute-intensive workloads.
Sales Process:
Direct engagement with Hyperstack's sales team proved challenging during this research; multiple inquiries reportedly received no response. Consequently, this assessment relies entirely on information gathered from their public website, documentation, and self-service platform interface. The platform emphasizes self-service deployment via dashboard or API ("Infrahub API").
Data Centers:
Hyperstack operates across three primary regions: Canada, Norway, and the USA. Their documentation states that infrastructure is housed in Tier 3-certified data centers, which also hold SOC 2 Type II certification.
SLA & Uptime:
While Hyperstack utilizes certified Tier 3 / SOC 2 infrastructure, specific uptime percentage guarantees or details of a formal SLA were not found in readily accessible public documentation during this research.
Additional Services/Software:
Hyperstack offers a variety of NVIDIA GPUs (H100 SXM/PCIe, A100, L40S, etc.). Networking options include standard Ethernet, high-speed Ethernet with SR-IOV, and InfiniBand, specifically for their large "Supercloud" cluster offerings. They provide managed Kubernetes services and standard OS images. An integrated, comprehensive MLOps platform was not identified; users likely need to deploy and manage their own MLOps tools on the provided infrastructure. API access is available for automation.
Specifications:
Cloud Minders
Website: https://www.thecloudminders.com/
Company Overview:
Cloud Minders, founded in 2021 and based in Atlanta, GA, provides GPUaaS solutions.
Sales Process:
The sales engagement during this research was positive, featuring a good meeting and a technically in-depth discussion. Cloud Minders demonstrated a responsive and detailed process, providing comprehensive answers via document and setting up a dedicated Slack channel for continued communication and support. This indicates a high-touch, technically knowledgeable approach.
Data Centers:
The primary infrastructure offered is located in Marietta, GA. The facility adheres to SOC 1 Type 2 compliance standards.
SLA & Uptime:
A formal SLA guarantees 99.5% uptime. Reliability is supported by the infrastructure standards (SOC 1 Type 2 compliant facility). Support via the dedicated Slack channel is guaranteed during standard business hours.
Additional Services/Software:
Cloud Minders focuses on providing HGX H100 server infrastructure with high-spec components (Intel Xeon Platinum CPUs, 2TB RAM, and large local NVMe). High-speed interconnect networking will be available in Q2 2025. They offer optional, low-cost NAS ($10/TB/mo). The offering does not include an integrated MLOps platform, ML/AI engineering consulting support, or provider-managed monitoring tools (dashboards/alerts). Service includes base OS/driver setup.
Specifications:

TCO Note: Pricing uses a base rate with discounts applied for monthly (20%) or annual (35%) commitments. The rate includes significant local NVMe storage (~31TB/node) and expert support during business hours. Optional NAS is very competitively priced ($10/TB/mo).
Bare Metal Providers Comparison

Marketplaces
Cudo Compute
Website: https://www.cudocompute.com/
Company Overview:
Cudo Compute provides GPUaaS, offering both bare-metal and community-sourced virtual machine access to a range of NVIDIA GPUs.
Sales Process:
Communication was extensive via email, with the Cudo team asking detailed, clarifying questions about workload requirements before providing specific options. They did not provide a formal proposal to our RFP; only an email with a pricing offering was shared.
Data Centers:
Cudo Compute offers services from multiple global locations, including confirmed availability in Norway, Finland, and Luxembourg for the requested resources. The provided materials did not detail Specific Data Center Tier ratings and compliance certifications.
SLA & Uptime:
Cudo Compute provides a public SLA for Committed Resources, guaranteeing 99.5% uptime, backed by a service credit structure. Support availability for issue resolution varies by priority. Critical (P1) support is available 24/7, while lower-priority issues adhere to extended business hours.
Additional Services/Software:
Cudo does not currently offer integrated MLOps platforms or direct ML/AI engineering consulting/support. They can pre-install frameworks for a setup fee ($450 quoted). Management is via dashboard, CLI, or API.
Specifications:
TCO Note: Pricing is tiered based on commitment length (1, 3, 6, 12 months quoted), location, and network choice. A setup fee applies for framework pre-installation.
Prime Intellect
Website: https://primeintellect.ai
Company Overview:
Prime Intellect operates a compute platform focused on AI/ML workloads. Their model appears to involve aggregating GPU resources, potentially combining traditional data center capacity ("Secure Cloud") with distributed or community-sourced compute ("Community Cloud"). They also develop open-source frameworks for distributed AI model training.
Sales Process:
The sales interaction was responsive, involving quick follow-up questions to clarify requirements (GPU type, specific needs, target pricing) before providing a detailed quote quickly. They offered fast spin-up times (days) for reserved instances. However, they didn’t provide a complete formal proposal for our RFP.
Data Centers:
The specific reserved instances quoted were located in Texas, USA. Public information regarding other potential locations, specific Data Center Tier ratings, or comprehensive compliance certifications is limited.
SLA & Uptime:
Prime Intellect quotes the following configuration for us: Each node consists of 8xH100 80GB NVLink, a Dual AMD 9354, 64 Cores at 3.25 GHz, 1536 GP RAM, 4x3.8TB NVME, and 2x10Gdps NICs. Initial communications did not provide specific uptime guarantees or details. Technical assistance is offered via Discord and 24/7 live chat through their platform.
Additional Services/Software:
Access is facilitated through the Prime Intellect compute platform, which allows VM access, scaling, and shared team accounts and utilizes pre-installed frameworks. While offering a platform layer, there is no comprehensive, integrated MLOps suite.
Specifications:
TCO Note: Prime Intellect offers very competitive pricing for reserved H100 SXM5 compute. The rate includes substantial local NVMe storage per node. Costs for additional storage and, crucially, data egress were not specified. InfiniBand networking represents an additional cost if needed.
RunPod
Website: https://www.runpod.io
Company Overview:
RunPod operates a GPU cloud platform offering compute via two distinct models: Secure Cloud (utilizing partner Tier 3/Tier 4 data centers) and Community Cloud (leveraging vetted, peer-to-peer providers). They provide GPU Pods (On-Demand and Spot instances) and a specialized Serverless platform designed for AI/ML inference and training workloads.
Sales Process:
The RunPod team focused on understanding the specific use case and offered onboarding credits for testing. For technical questions, they had access to a senior support engineer. They also offer tiered discounts for reserved pods and usage-based optimization for Serverless, indicating a flexible, customer-focused approach. However, a formal RFP response document was not provided.
Data Centers:
RunPod utilizes a mix of infrastructure. Its Secure Cloud offering relies on partner data centers that meet Tier 3 or Tier 4 standards, ensuring higher reliability and security suitable for enterprise workloads. Its Community Cloud offering uses a globally distributed network of vetted individual providers.
SLA & Uptime:
RunPod emphasizes reliability for its Secure Cloud offering. While a specific uptime percentage guarantee (like the noted 99.5%) was not confirmed in the proposal during this research, they provide access to senior support engineers for technical assistance.
Additional Services/Software:
RunPod provides GPU access via Pods (similar to VMs/containers, available On-Demand or interruptible Spot) and a dedicated Serverless platform. The Serverless option is highlighted for AI inference, featuring autoscaling and optimization for low cold-start times. Networking within data centers is high-speed Ethernet (up to 200 Gbps mentioned). RunPod does not provide a comprehensive, integrated MLOps suite covering the entire ML lifecycle; users typically integrate their preferred tools. API/CLI access is available.
Specifications:
TCO Note: Pricing for reserved pods offers significant discounts (up to 30% quoted) based on term length and prepayment. Serverless pricing is usage-based, with the potential for significant optimization and discounts (up to 60% mentioned) based on traffic patterns, requiring testing. Onboarding credits were offered.
Marketplaces Comparison
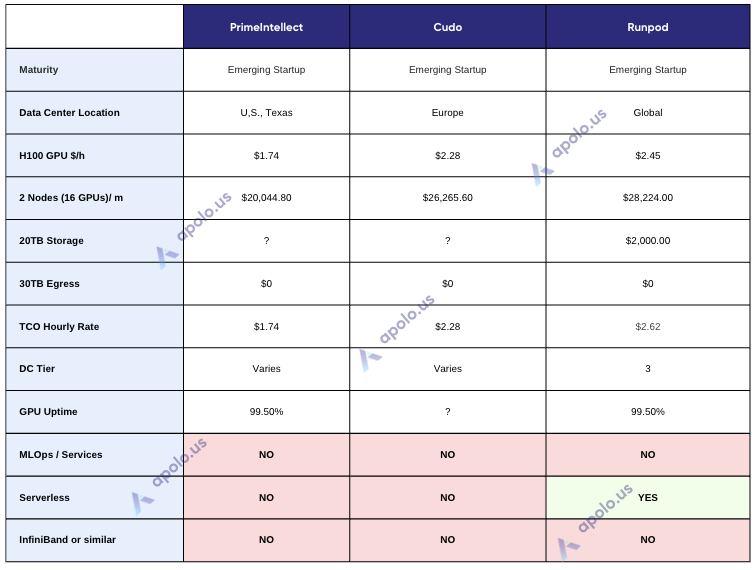
Hyperscalers
Amazon Web Services (AWS)
Website: https://aws.amazon.com
Company Overview:
AWS operates on a cloud computing business model, primarily driven by pay-as-you-go access to a wide array of IT resources and services over the Internet. It leverages massive economies of scale to offer computing power, storage, networking, databases, machine learning tools, and more without requiring upfront capital investment in hardware from the customer. Revenue comes from customer consumption of these services, billed based on usage metrics (e.g., instance hours, data storage, and data transfer).
Sales Process:
During our engagement with AWS, we had two sales calls led by a dedicated manager who explained their available GPU instances and differentiated between various pricing structures, including spot, on-demand, 6-month commitments, and longer terms of one year or more. Currently, they offered a significant price reduction specifically for a 6-month reservation of resources, with the condition of requiring full prepayment for the entire committed period.
Data Center:
AWS operates a massive global infrastructure organized into Regions worldwide. Each Region is a separate geographic area containing multiple, isolated Availability Zones (AZs). AZs consist of one or more discrete data centers with redundant power, networking, and connectivity housed in separate facilities. This structure provides high availability, fault tolerance, and low latency.
SLA & Uptime:
The EC2 SLA typically guarantees a certain level of monthly uptime percentage (e.g., 99.99% for instances deployed across two or more AZs in the same Region). Single-instance SLAs are generally lower (often 99.5% or 99.9%, depending on storage type). If AWS does not meet the SLA commitment, customers are eligible to receive service credits.
Additional Services/Software:
Beyond basic compute (EC2) with H100s, AWS offers a comprehensive ecosystem relevant for GPU-intensive workloads: Amazon SageMaker, an end-to-end platform for building, training, and deploying ML models, which comes at around 15% premium to the compute price.
Specifications:
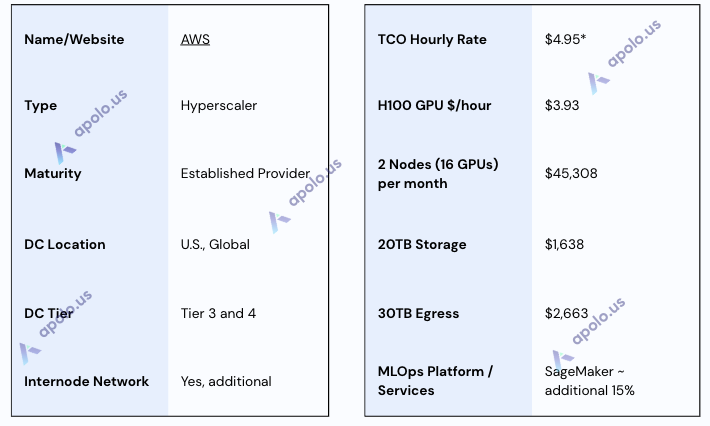
Pricing varies significantly by region, commitment term, and payment option. Storage (EBS, S3) and Data Transfer Out (Egress) are priced separately and added to the total cost.
Google Cloud Platform (GCP)
Website: https://cloud.google.com
Company Overview:
Google Cloud Platform operates on a pay-as-you-go cloud computing model, leveraging Google's extensive global infrastructure, networking, and expertise in data analytics and machine learning. It offers various services, including compute, storage, networking, databases, and prominent AI/ML platforms, emphasizing open-source contributions (like Kubernetes) and data-driven solutions.
Sales Process:
Our engagement with GCP involved an initial call with a sales representative. However, a formal proposal was not received as the follow-up occurred approximately two weeks later, by which time our intake process for offers had already concluded. Therefore, the pricing and configuration details mentioned in this profile are based on publicly available GCP pricing information and calculations derived from that data, not on a specific quote provided by GCP sales for this requirement.
Note: This pricing reflects On-Demand rates. Significant cost reductions are possible with 1-year or 3-year Committed Use Discounts (CUDs), which were not factored into this specific calculation as no formal proposal including CUDs was received. GPU CUDs can offer up to 55% savings for a 3-year commitment. All pricing is region-dependent and subject to change.
Data Center:
GCP utilizes a global network of Regions, subdivided into multiple Zones (typically 3+ per region), representing physically separate data centers within that geographic area. This structure supports high availability and fault tolerance. GCP emphasizes its high-speed, private global network backbone connecting these facilities, along with robust physical security, compliance certifications (ISO, SOC, PCI DSS, etc.), and a focus on carbon-neutral operations.
SLA & Uptime:
Google Cloud offers SLAs for core services like Compute Engine. Availability guarantees depend on the deployment architecture (e.g., higher guarantees for instances deployed across multiple zones within a region vs. single-zone instances). If GCP fails to meet the uptime commitment, customers are typically eligible for service credits based on the SLA terms.
Additional Services/Software:
Beyond core compute with H100s, GCP offers a suite of relevant services: Vertex AI (AI/MLOps platform), Google Kubernetes Engine (managed Kubernetes service), Cloud Storage (object storage), Persistent Disk (block storage), Cloud Interconnect (dedicated network connection), Batch (batch job processing), Cloud Monitoring, and integration with data analytics tools like BigQuery.
Specifications:
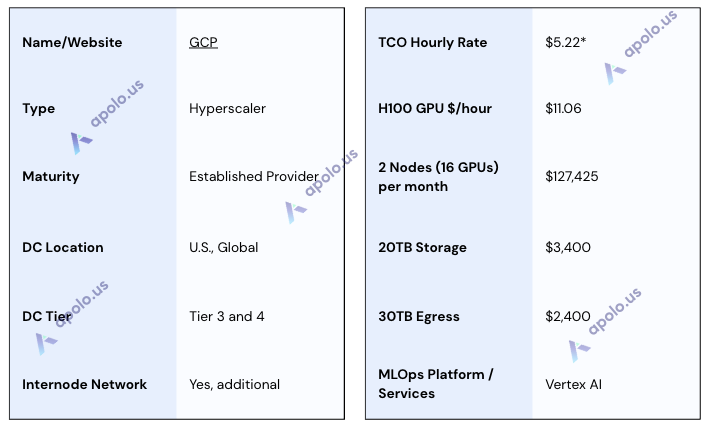
TCO Note: This pricing reflects On-Demand rates. Some cost reductions are possible with 1-year or 3-year Committed Use Discounts (CUDs), which were not factored into this specific calculation as no formal proposal including CUDs was received. All pricing is region-dependent.
Hyperscalers Comparison

Conclusion
As AI workloads continue their rapid expansion, GPU-as-a-Service emerges as not merely an option but a strategic imperative for data center providers. The findings of this report underscore that entering the GPUaaS market is complex yet rewarding—success demands careful attention to infrastructure selection, transparent pricing models, strategic partnerships, and a powerful software stack to ensure efficiency, profitability, and customer satisfaction. Providers who navigate these challenges thoughtfully will position themselves strongly against hyperscalers, attract enterprise customers seeking predictable costs and localized infrastructure, and ultimately drive substantial new revenue streams in a rapidly evolving market.
