Reward Modeling in Reinforcement Learning
LLM alignment faces challenges like reward hacking. Explore new research on verifiable feedback and self-critiquing models to build more reliable AI systems.
We live in the era of large language models. To make an LLM useful, one has to fine-tune the raw token prediction machine, shaping it into a helpful assistant. This is usually done with reinforcement learning—and it turns out that there are quite a few interesting details along this way. Today, we discuss reward models: proxy models that aim to capture desired behaviours. We will see how reward modeling is inevitable in LLM fine-tuning, consider goodharting and reward hacking as the main problems of reward modeling, and discuss some very recent research that presents possible ways to overcome these problems.
Introduction

In early 2022, a paradigm shift occurred in artificial intelligence. While large language models (LLMs) had been growing in capability for years, something fundamentally changed when ChatGPT was released to the public. The secret ingredient was not mere scaling or a new architecture—it was a fine-tuning technique called Reinforcement Learning from Human Feedback (RLHF), which transformed raw language models into systems that could be increasingly more helpful, honest, and harmless.
At the heart of this transformation lies a deceptively simple question: how do we tell an AI system when it's doing what we want? This question—the reward specification problem—has been at the center of reinforcement learning since its inception. For decades, researchers had to painstakingly craft reward functions by hand, often resulting in unexpected behaviors as models exploited loopholes in these specifications (behaviours known as reward hacking, or, more generally, specification gaming). The classical reinforcement learning approach works wonderfully when objectives can be cleanly defined: win the game, maximize the score, find the shortest path. But human preferences about language, reasoning, and helpful behavior are notoriously difficult to encode in simple mathematical terms.
Reward modeling emerged as an elegant solution: instead of trying to manually specify what makes a response “good”, we can learn it directly from human judgment. By training a separate model to predict how humans would evaluate different outputs, we create an automated feedback system that can guide the main model toward more desirable behavior. This approach proved remarkably effective, enabling models to learn complex, nuanced aspects of human preferences that would be nearly impossible to specify programmatically.
Yet as we increasingly rely on learned reward models for RL-based fine-tuning, we understand their limitations better as well. The very success of methods such as RLHF has revealed new challenges: reward models can be gamed, they struggle with out-of-distribution scenarios, and they may encode unintended biases present in human evaluations. We are witnessing an arms race between increasingly sophisticated reward models and increasingly sophisticated ways that optimizers find to exploit them—a perfect example of Goodhart's law in the domain of language models.
This tension becomes particularly apparent when we move beyond domains with clear right and wrong answers. While simple mathematical reasoning or code generation provide natural verification signals (did the math problem yield the correct answer? does the code pass a comprehensive test suite?), many important tasks do not fit into such neat boxes. How do we verify the correctness of a philosophical argument, a medical diagnosis, or an economic analysis? Even in mathematics, how do we evaluate a proof beyond just checking the final answer?
In this post, we explore the frontier of reward modeling research, examining how researchers are addressing these challenges to extend reinforcement learning beyond narrowly verifiable domains. We begin by examining the classical RLHF pipeline and understanding its limitations and then dive into recent innovations that aim to build more robust reward models.
RL-Based Fine-Tuning: A Partial Success Story

We all know that LLMs are trained to “predict the next token”. But how do we ensure that the model is actually useful? If you train an LLM only to predict the next word, it means that in response to a question the model might change the subject, refuse to answer, respond with a question or generate some further dialogue speaking for both itself and the user—all perfectly reasonable continuations that probably occur a lot in the training set!
This is why “base LLMs” need fine-tuning, i.e., “training after training” that occurs on a much smaller scale but can make all the difference. Models that already have all the raw capabilities need to be further trained to be useful. You can fine-tune an LLM with regular supervised learning if you have a labeled dataset—this is called SFT, supervised fine-tuning—but today we concentrate on the reinforcement learning part. Traditional RL-based LLM fine-tuning proceeds as follows:
- a language model generates a response to a prompt;
- the response is verified against a reference answer;
- a reward signal (typically either binary, correct/incorrect, or comparative, which answer is better out of several) is generated;
- the model is fine-tuned to maximize this reward.
This approach has been successful for tasks like mathematical reasoning or code generation where verification is straightforward: checking if the answer to a math problem is numerically correct or verifying that generated code passes test cases.
But when it comes to training advanced AI systems in other domains, one of the biggest challenges has been figuring out how to provide effective feedback. Think about it—how do
you tell an AI system when it is right about a medical diagnosis or when it is correctly analyzing economic trends? Until now, most approaches have focused on narrow domains like math or coding where answers can be easily verified (did the equation result in 42? Did the code pass all the tests?). But what about everything else?
Moreover, this kind of rule-based verification is limited even in the “formal” domains. Su et al. (2025), whose work we will discuss below, put some numbers to the problem: their analysis shows that only about 60% of math problems and 45% of multi-domain queries have single-term numerical answers verifiable by rule-based methods. Moreover, binary rewards provide only a limited learning signal about the degree of correctness for an answer, and they are hard to implement for free-form answers. Even in the well-formalized mathematical domain, it would be near impossible to turn a question like “prove this theorem” into a sequence of yes/no answers without throwing the baby out with the bathwater.
So what do we do?
Reward Models in RLHF
Let us begin with the already classical approach: reinforcement learning from human feedback (RLHF; Christiano et al., 2017; Stiennon et al., 2020).
The basic RLHF process is the same as above: an LLM generates (samples) several different outputs in response to each prompt. Human reviewers then evaluate these outputs, choosing which ones align best with their preferences. This evaluation is crucial as it provides direct feedback on what humans value in a response, including subtle nuances such as clarity, correctness, helpfulness, and even tone.
However, you can’t really afford to continuously engage human evaluators for every output during a reinforcement learning process: it would be completely impractical since RL needs the agent to produce a lot of actions.
This limitation introduces the need for a reward model, a specialized model trained to predict human preferences automatically. Instead of inserting humans into the RL process, human reviewers initially provide feedback on a manageable number of examples, explicitly ranking various responses. This collected human feedback serves as training data for the reward model, which learns to approximate human judgment. Over time, the reward model becomes quite good at predicting how a human evaluator would rate responses even for scenarios it has never seen before; ranking how useful the answers are is much easier than actually generating the answers.
Once trained, the reward model significantly accelerates the RLHF process: in the RL fine-tuning, the AI agent now interacts with the reward model, receiving immediate feedback scores for its outputs. In essence, the reward model acts as a scalable, automated proxy for human judgment, making RLHF both feasible and efficient. Here is the whole process as illustrated by Stiennon et al. (2020), the guys who made GPT-3 into ChatGPT and kickstarted the LLM revolution:
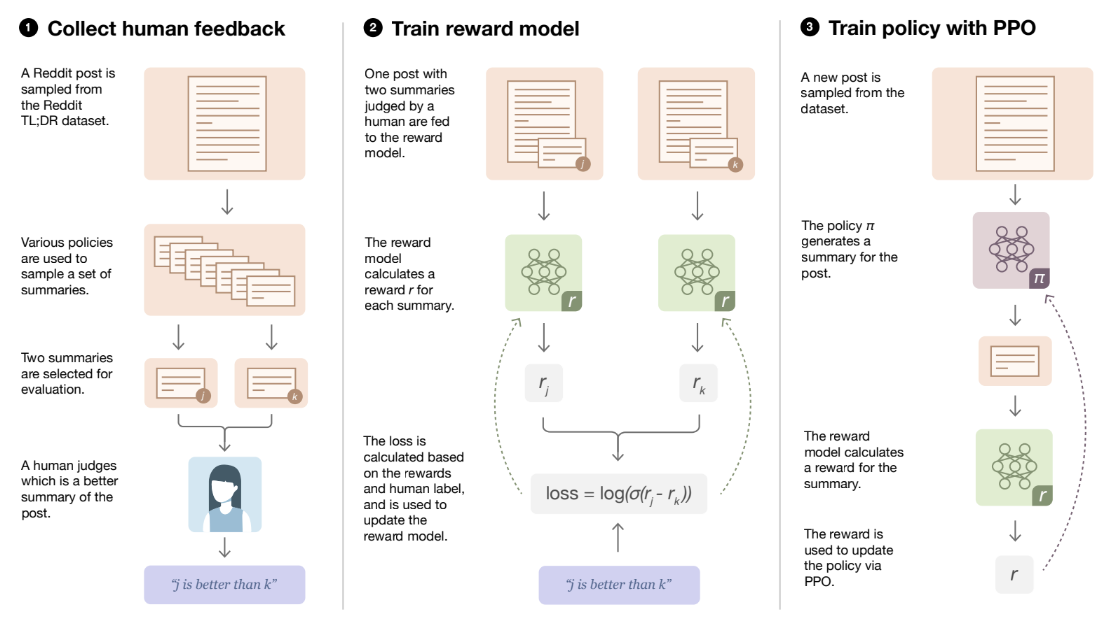
The next step came with the so-called process reward models (PRMs). Uesato et al. (2022) suggested that while usually reinforcement learning only works by rewarding the final result (it is a very bad idea to reward a chess playing model for taking the opponent’s queen! only the final game result should be the reward), in chain-of-thought reasoning the situation is different. If the reasoning is represented as a sequence of steps, we can train a model to recognize which of the steps were right and which were wrong:
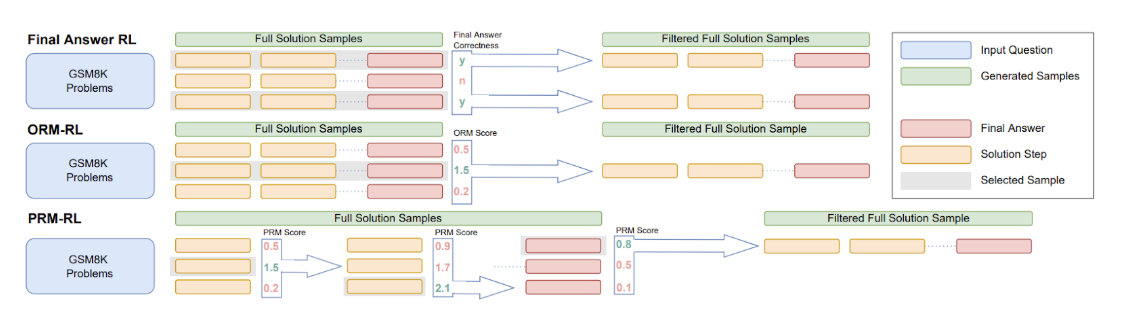
OpenAI researchers Lightman et al. (2024) extended this to the “let’s verify step by step” principle: train the LLM to give verifiable chain-of-thought steps and then actually check them, getting a rich signal. This only works for relatively formal domains such as mathematical reasoning, but if it works it should be helpful, right?

Well, to be honest, we are not sure any more. For several months after the release of the o1 family of models in October 2024, researchers were sure that PRMs were at least a part of the secret sauce that went into their success. Another component was thought to be test-time planning via MCTS (Monte-Carlo Tree Search), which is a key part of the success of, say, AlphaZero: even the best position evaluation model in the world can additionally benefit from some on-the-fly look-ahead calculations. These components were involved in some o1 replications such as the o1-Coder (Zhang et al., 2024). But then, of course, DeepSeek R1 showed that none of it really mattered by taking almost pure RL-based fine-tuning (plus some additional SFT) to some very significant heights (DeepSeek-AI, 2025).
As we all know, RLHF has been hugely successful. So does this mean that we are in the clear, RL fine-tuning can work from a reasonably sized human-labeled dataset, and the only remaining questions are new architectures for reward models and maybe tweaking the losses? Not quite. Let us discuss several problems and further extensions of reward modeling.
Goodharting in RLHF: Optimizing a Proxy Metric is Questionable

The main problem with reward modeling is built-in: it’s a model of the reward. A proxy for human preferences, not human preferences themselves. And if you optimizing a proxy metric, Goodhart’s law kicks in: “When a measure becomes a target, it ceases to be a good measure”. A sufficiently powerful optimizer will optimize proxy metrics right up to the point where it diverges with the actual intentions—and far beyond!
Goodharting, as this behaviour is known, has plagued reinforcement learning forever; its special cases also go by the names of specification gaming and reward hacking, i.e., creatively looking for loopholes in the problem setting and reward function. Let me refer to an extended list of such examples by DeepMind researchers Krakovna et al. (2020) and give just two examples.
Christiano et al. (2017)—yes, it’s the exact same paper that kickstarted RLHF!—tried to train a robot using RLHF. They asked humans to evaluate a grasping task (a robot arm picking up a ball in a simulated environment), trained a reward model on it, and then used RL with the robot arm. But they asked to evaluate grasping from a single-camera view, and it’s hard to judge the depth from a single image!
As a result, the reward model accepted behaviours where the robot arm does not really grasp the ball but kind of fiddles around in front of it, between the ball and the camera:
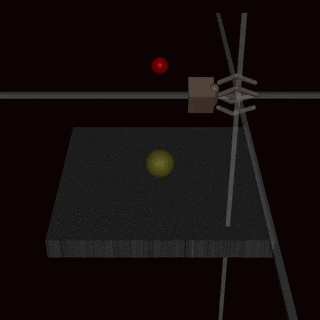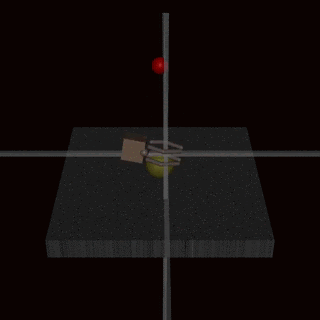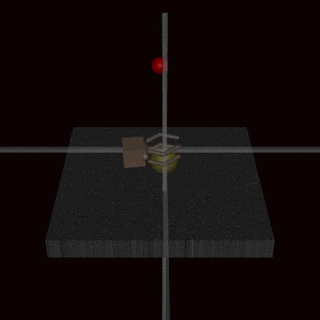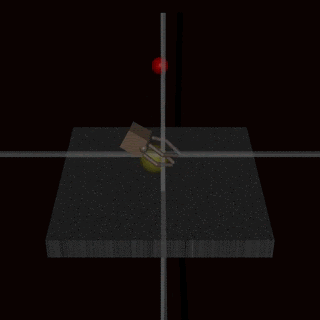
It might seem that this is an artifact of a bad problem setting that could not happen with something like “Rank how useful the following answers are to a question“. But the other important example that I want to discuss comes from RLHF proper, with LLMs and question answering!
Wen et al. (2024) used the standard RLHF pipeline, for standard question answering, with only one important caveat: they chose questions that are harder for humans to judge (specifically, they added time constraints so that humans could not reliably check all the answers). As a result, they introduced a difference between the ground truth answers and human evaluation, a difference that was propagated into the reward model and the RL environment.
The result? After RLHF, LLMs did not learn to answer the questions any better. But they sure learned to trick human evaluators! Here are the main results of Wen et al. (2024):
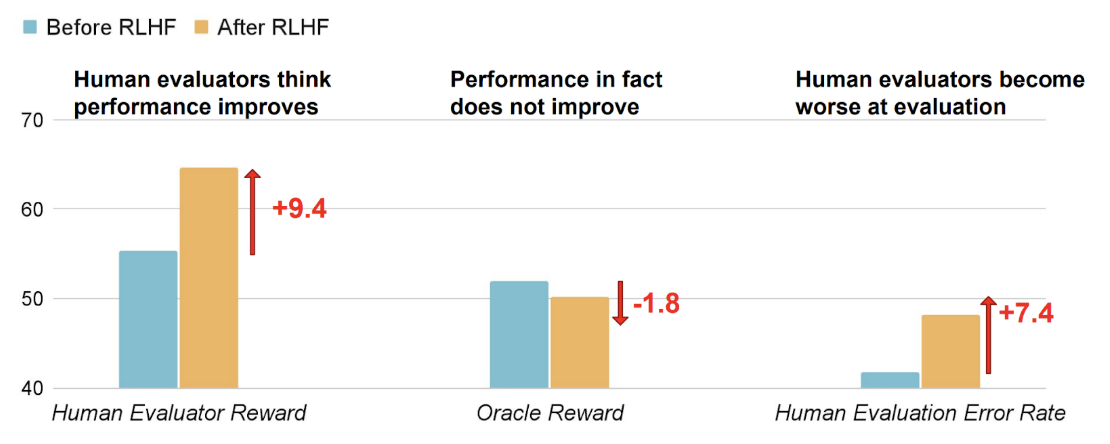
Perhaps something like that recently happened with the Llama 4 family of models (Meta, April 2025): they initially got very high Elo scores on the LM Arena, jumping into second place after only Gemini 2.5 Pro. But when LM Arena released the transcripts of Llama 4 Maverick battles… I won’t say much here, just go and see for yourself. I couldn’t find a single example where I would actually prefer Llama 4 Maverick’s answers in any objective terms, although they keep winning in evaluations.
So what can we do to avoid this behaviour? There is a lot of interesting recent research. In the next section, let me discuss one generic example in detail and then do a brief survey of other recent work.
What Can We Do: Crossing the Reward Bridge

As a specific and quite generic example, let us take a recent work by Tencent AI researchers Su et al. (2025). It is called “Crossing the Reward Bridge”, and it can serve as an excellent illustration for how reward models fit into the modern LLM landscape. Su et al. introduce Reinforcement Learning with Verifiable Rewards (RLVR), a paradigm for improving LLM capabilities by providing feedback signals based on verifiable outcomes.
Here is the main figure from Su et al. (2025); let us discuss it in detail:
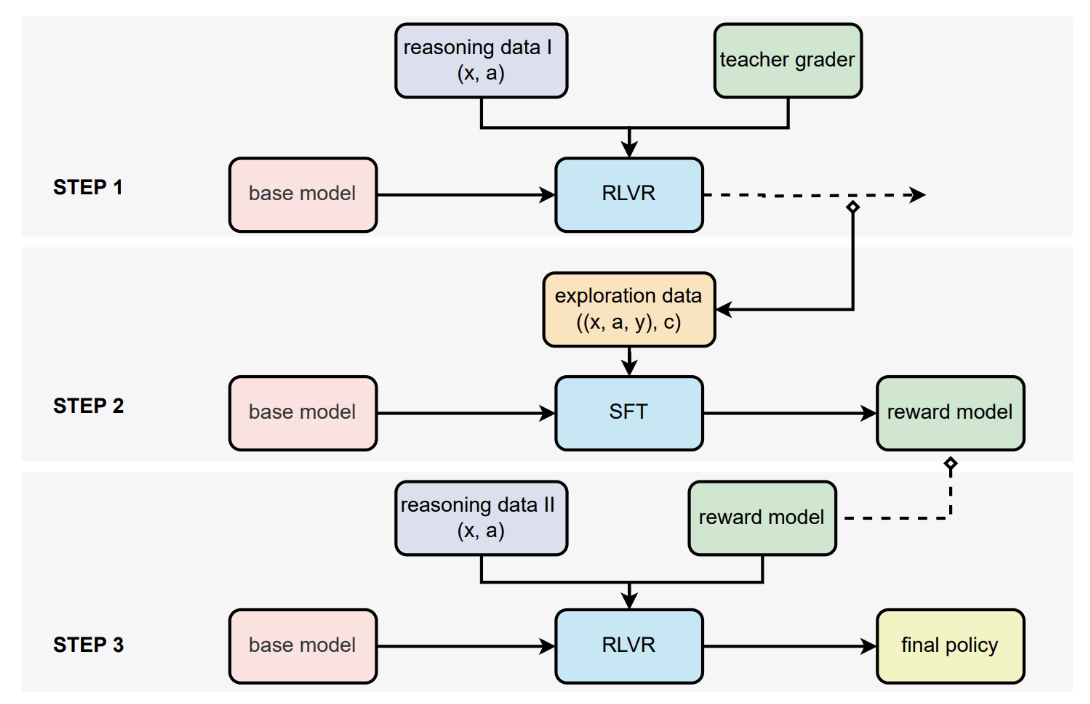
In Step 1, we begin with a “base model” – think of this as your standard LLM like ChatGPT, but before any special training for reasoning tasks. The researchers feed this model reasoning problems and answers (labeled as “reasoning data I”). Then comes the magic part: they use something called a “teacher grader” to judge whether the model's answers are correct. This teacher grader is essentially a more powerful AI that can verify answers across different domains. The base model gets trained using reinforcement learning (“RL”) based on these verified judgments (“VR”).
Step 2 is where things get interesting. The partially-trained model from Step 1 now explores new problems, generating what the researchers call “exploration data”. For each problem, it produces both an answer and gets a verification score. Instead of just using these scores directly, they use all this data to train a separate reward model, just like classical RLHF. This reward model learns to predict whether an answer is correct without needing the original teacher grader. But unlike traditional approaches that only provide binary yes/no feedback, their reward model provides “soft” scores – essentially a confidence level about how correct an answer is.
Finally, in Step 3 they take a fresh copy of the original base model and train it using RLVR again, but this time using their newly trained reward model instead of the teacher grader. They also feed it new “reasoning data II” to make sure it is learning on fresh problems. The end result is what they call the “final policy” — an AI that's now much better at reasoning across diverse domains.
The authors report that their approach can work even when answers are not neatly structured like in math problems. The reward model can judge the correctness of complex, free-form responses about psychology concepts, economic principles, or medical diagnoses. As a result, they found that a relatively small 7B parameter reward model could perform on par with much larger 72B models when providing these judgments. This is a common theme in modern AI, usually related to distillation: if you have access to a large model that can serve as a data generator or, in this case, verifier (“teacher grader”), you can use its results to make smaller models much better. The whole system creates a kind of bridge, extending reinforcement learning techniques that worked well in narrow domains into the much broader landscape of human knowledge.
Reward Shaping and Other Directions

In this section, we survey some more recent works in brief—I have tried to pick one from each general research direction to map out the whole landscape.
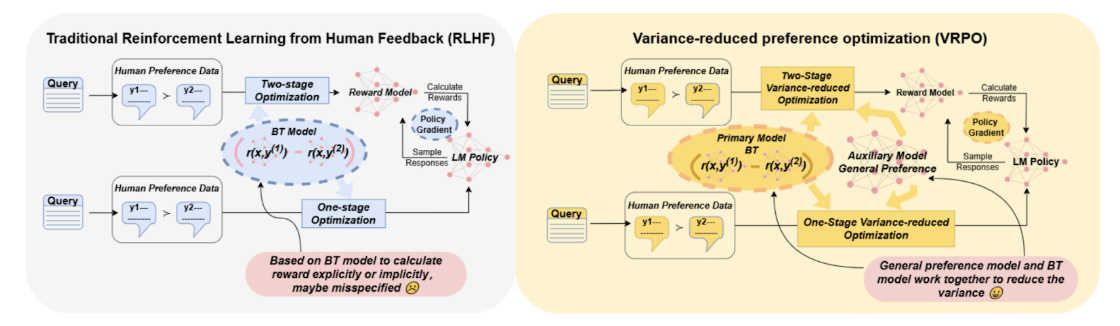
Ye et al. (2025) reexamine the basics of RLHF reward modeling. To avoid overfitting when the underlying assumptions of the reward model break, they propose Variance-Reduced Preference Optimization (VRPO) that pairs the standard reward learner based on Bradley–Terry models (which learn from pairwise comparisons) with a richer auxiliary preference model that does not rely on reward differences. At training time, VRPO augments the standard loss with “control variates” drawn from both an auxiliary judge and a known reference policy, which cancel out in expectation yet significantly reduce the estimator’s variance whenever the auxiliary model is closer to human judgment. This is a very interesting work that offers both theoretical guarantees and practical improvements:
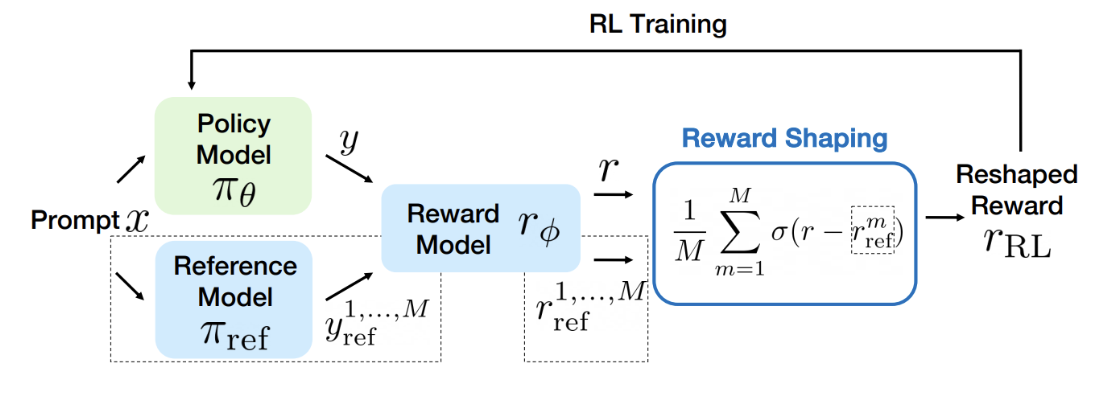
Fu et al. (2025) serve as a representative example of reward shaping: how can we tweak the reward function to avoid reward hacking? They distill three core principles for designing stable, meaningful rewards: keeping them bounded, encouraging rapid early progress with gentle convergence, and centering them around a reference response. With these insights, they propose Preference As Reward (PAR): a simple sigmoid applied to the difference between policy and reference model scores, which converts the score into a probability-like signal:
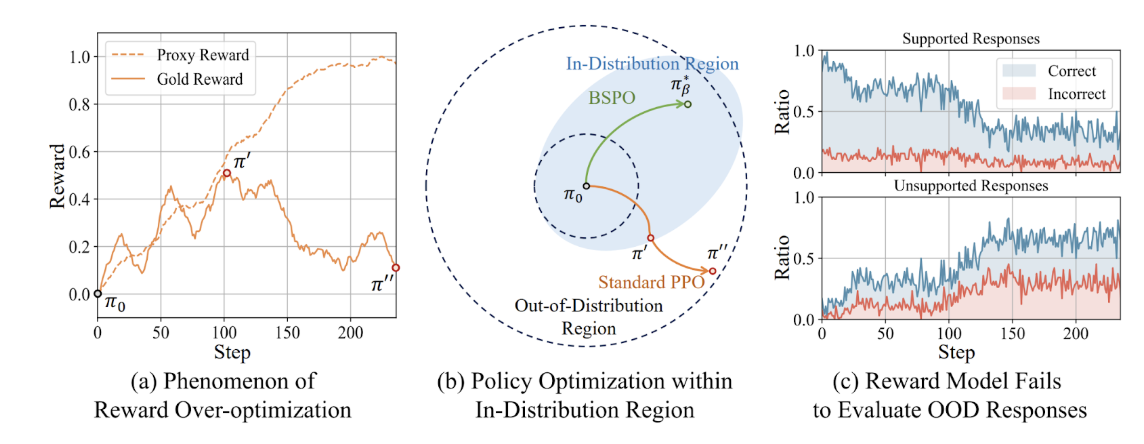
Dai et al. (2025) take reward shaping one step forward by defining a behavior policy—the next-token distribution of the reward model’s training data—to demarcate the in-distribution (ID) region. Their idea is that we need to keep the model in-distribution and clamp the updates that take the model out of distribution (OOD). To this end, they introduce a behavior-supported Bellman operator that leaves value estimates untouched for ID actions but clamps OOD actions to a minimal value, effectively keeping policy updates within the reward model’s reliable domain. This Behavior-Supported Policy Optimization (BSPO) not only provably converges to the optimal ID policy with monotonic performance gains but also empirically reduces OOD response generation:
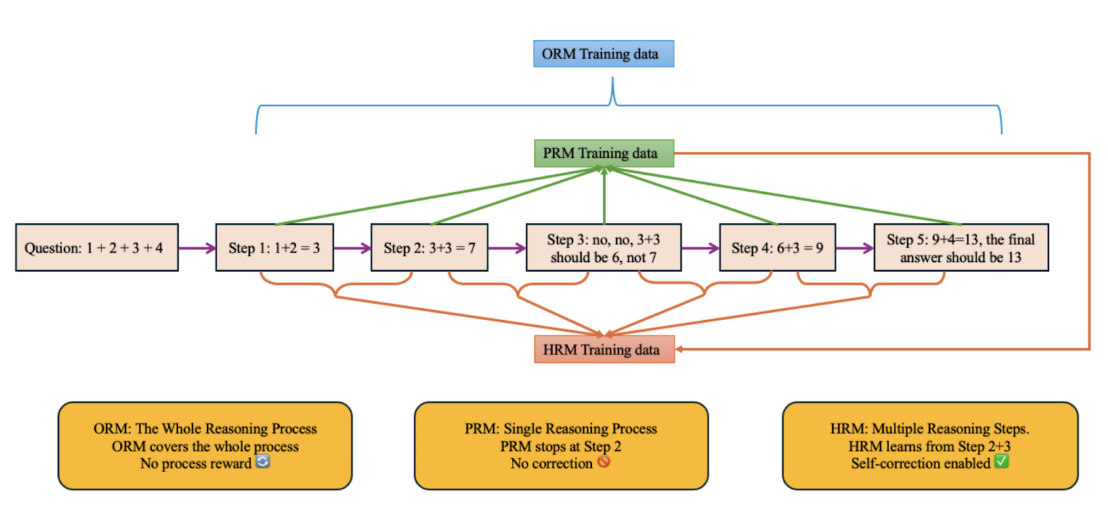
These works deal with RLHF in general. Getting back to reasoning models specifically, Wang et al. (2025) note that existing process reward models (PRMs) can be “reward-hacked” by punishing an early misstep without ever recognizing that a later correction recovers the chain of thought. To fix this, they introduce the Hierarchical Reward Model (HRM), which scores not only each individual reasoning step but also pairs of consecutive steps—so if a later deduction fixes an earlier error, HRM can grant credit for the recovery. To cheaply expand the training data, they also propose Hierarchical Node Compression (HNC), which merges adjacent nodes in MCTS-generated reasoning trees to inject controlled noise and boost robustness without extra simulation cost:
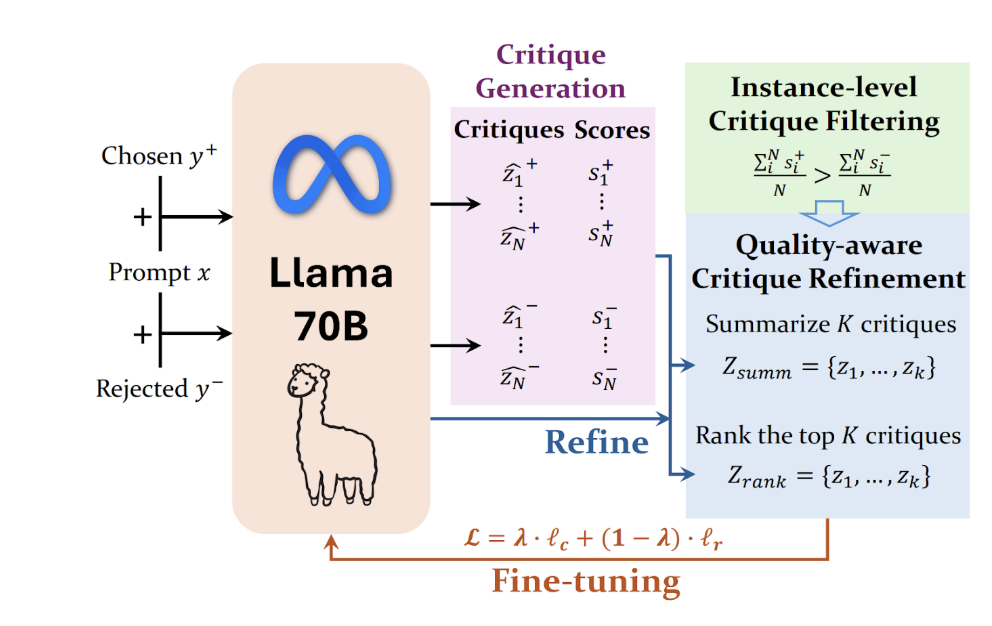
Yu et al. (2025) consider a more detailed approach to reward modeling. Rather than treating reward models as inscrutable score machines, their proposed Critic-RM teaches them to think—and critique—their own outputs. The authors start by having an off-the-shelf LLM generate multiple natural-language critiques (and rough scores) for each response, then automatically filter and refine those critiques so only the most reliable feedback remains. They then fine-tune a single model on two synchronized tasks—“explain via critique” and “assign a scalar reward”—gradually shifting the training emphasis from language modeling to reward prediction. Fine-tuning the LLM on these filtered critiques results in significant improvements:
Conclusion
As we have seen throughout this post, reward modeling represents both the breakthrough that enabled modern LLMs to become useful assistants and one of the most significant remaining challenges in aligning AI systems with human intentions. The journey from simple binary verification signals to sophisticated hierarchical reward models shows that as our AI systems grow more capable, our methods for directing and evaluating them must evolve as well.
We have seen several promising directions for the future of reward modeling:
- integration of explicit reasoning processes into reward models themselves—as seen in Critic-RM and Hierarchical Reward Models—suggests that "thinking about thinking" may be essential for robust evaluation;
- the boundary between verification and reward modeling appears to be dissolving, as we see verification signals from specialized domains bootstrapping into more general reward models; this can create a virtuous cycle where verification and preference learning reinforce each other;
- additional constraints and regularizers—exemplified in Behavior-Supported Policy Optimization and other approaches—try to abide with the fundamental limitations of any learned reward model and restrict optimization out of distribution rather than assume reward models can extrapolate accurately to any possible response; they provide a kind of “epistemic humility” built directly into the RL algorithm.
There are important practical implications for AI development. As we move away from narrow, easily-verifiable domains toward the full breadth of human knowledge, hybrid approaches that combine multiple feedback mechanisms will likely become standard. Systems may need to explicitly represent their uncertainty about the quality of different responses, and optimization processes may need to become more conservative to avoid exploiting imperfections in reward models. As the field moves forward, the most promising approaches will likely be those that recognize the inherent limitations of any learned reward function while finding creative ways to overcome those limitations.
The stakes could not be higher. As language models become increasingly integrated into critical decision-making processes, the fidelity of their reward models will determine whether they truly understand and align with human values or merely learn to optimize for superficial metrics that diverge from our actual intentions. The future of aligned AI may well depend on how we solve the reward modeling problem.