Go Back
Author: Constantine Goltsev
Published

Imagine a graduate student who never sleeps. Give them a baseline solution, a simple directive of ”making this number go up”, and unlimited compute. They tinker endlessly: swap losses, add regularizers, tweak architectures, mine tricks from papers, test everything. When the metric improves, they remember; when it drops, they backtrack. Now imagine this student has read every paper in the field and can test a hundred ideas overnight. This is no longer imagination. Google DeepMind has built this system, and it is already beating human experts across multiple scientific domains.

Science has always been a dialogue between human creativity and mechanical labor. Darwin spent eight years dissecting barnacles before his insights crystallized into evolution. Kepler calculated planetary orbits by hand for decades before discovering his laws. Today's scientists face their own form of tedium: endless parameter tuning, architectural tweaks, and benchmark chasing—the digital equivalent of barnacle dissection. What if we could delegate this grunt work to an AI system that never tires, never gets frustrated, and actually enjoys the grind?
“An AI system to help scientists write expert‑level empirical software” by Aygün et al. (Google DeepMind and Google Research, September 2025) proposes a general recipe for what the authors call scorable tasks: scientific problems with clear numeric optimization targets. The system produces methods that match or beat the best human-written baselines across a surprisingly wide spectrum: single-cell integration, COVID-19 forecasting, geospatial segmentation, whole-brain activity prediction in zebrafish, general time-series forecasting, and even numerical integration routines. The headline claim is both simple and audacious: if you can define a clean numeric score, you can treat method development as search over code. A code-rewriting LLM paired with intelligent tree search gradually climbs to expert-level performance—and often beyond.
This is not the first attempt at automated ML research. AutoML has been automatically tuning hyperparameters for years. Neural Architecture Search (NAS) explores network designs. What's different here is the level of abstraction: instead of searching over predefined spaces (architectures, hyperparameters), this system searches over arbitrary code changes. It's the difference between choosing from a menu and hiring a chef who can invent new dishes.
The paper's definition of “empirical software” is pragmatic: any code designed to maximize a measurable score on real data. Fit a segmentation model and report mIoU, forecast a curve and report WIS/MAE, integrate a difficult function and report the error: if there is a number that can serve as a trustworthy measure of success, it is a scorable task. This framing is more important than it looks. It turns “invent a method” into “search the space of working programs for the ones that score best”, a problem that is much better defined and hence much more amenable to automation.
Why does this matter? A typical ML paper might involve months of manual experimentation to achieve a 2-3% improvement on a benchmark. Graduate students and postdocs spend countless hours on hyperparameter sweeps, architecture searches, and feature engineering—work that's (currently) necessary but rarely intellectually stimulating. If we can automate this grunt work, we don't just save time; we fundamentally change what scientists can accomplish. A researcher could propose ten novel approaches in the morning and have optimized implementations by evening.
The system itself is very straightforward:
The search is classic exploitation/exploration over a tree of code versions. The LLM is not asked to solve the task in one shot but to propose mutations, i.e., semantic edits, guided by research ideas the system can find in papers, textbooks, search results, and prior solutions. Here is the main loop as illustrated by Aygün et al. (2025):

If that makes you think of AlphaGo’s combination of learned value functions with Monte‑Carlo Tree Search, you are not far off. The analogy is explicit in the references and in the way the authors talk about exploration policies and “breakthrough plots” that annotate where the score jumps after a code change.
At this point, you might ask: why do we need tree search at all? Can’t modern LLMs just go ahead and solve the problem? In reality, one‑shot code generation is brittle. Prior art like FunSearch already suggested that LLM combined with an automated evaluator beats single prompts for creative discovery; here the evaluator is the benchmark itself, and the LLM’s job is narrowed to “rewrite with intent”. The novelty is to generalize from an evolutionary loop to an explicit, budgeted tree search with research‑idea conditioning.

Aygün et al. (2025) are careful about the source of the LLM’s improvements. It is not just stochastic code search, the system explicitly injects research ideas into the prompt. Some ideas are provided by humans; others are mined automatically from the literature or from prior solutions, summarized into short method descriptors the LLM can use.
There’s a nice, specific example in the supplement: a prompt template that asks the LLM to summarize an algorithm (e.g., BBKNN for batch correction) into a minimal description and steps, and then those steps become instructions to write code that’s allowed to vary and optimize around that core idea:

This “idea distillation → code search” bridge is what makes the system feel like a real research assistant rather than a Kaggle‑only optimizer. It gives the LLM a vocabulary of building blocks—augmentations, encoders, preprocessing pipelines and the like—then lets the tree search discover useful recombinations and hyperparameter regimes.

The system runs many such candidates, gets scores, and expands the promising branches. When the score jumps, the paper’s breakthrough plots annotate the change that caused it—“added explicit delta features,” “consolidated temporal 1D CNN,” “8‑fold TTA,” etc.—which makes the search trace readable for humans. Here is an example given in the paper for the numerical integration problem:

You can literally watch the score plateau and then jump up again when the right change is introduced. If you have ever chased a metric in a numerical experiment, you will recognize this plot as a very typical outline of what happens in the process.
The genius of this approach lies in treating code improvement as a navigation problem. Just as GPS finds the best route through a city by exploring different paths, the system explores different code modifications to find the path to better performance. But unlike random exploration, it uses a sophisticated strategy borrowed from game-playing AI.

Remember how AlphaZero revolutionized chess and Go using Monte Carlo Tree Search (MCTS)? The same fundamental principle that helped AI master board games is now being applied to something far more complex: automatically writing and improving scientific code.
MCTS elegantly solves a classic reinforcement learning dilemma: finding the sweet spot between exploiting branches that already show promise and exploring new, untested paths. It's essentially an extension of the UCB (Upper Confidence Bound) algorithms to tree structures, fundamental stuff in RL theory.

This is exactly how Aygün et al. (2025) operate. Their system isn't thinking abstractly about "what to improve next". It's building a concrete tree where each node represents a version of a program, and edges represent specific code modifications. When a modification improves the target metric, the system becomes more likely to explore that branch further. The key requirements are a concrete numerical metric to optimize (analogous to win probability in Go) and experiments that are cheap enough to run thousands of times.
Unlike Go with its fixed rules, this system can make any code changes: tweaking model architectures, adding preprocessing steps, rewriting loss functions, combining methods—the search space is vast, but MCTS navigates it efficiently. The result is a focused search tree where "good ideas" emerge as nodes that consistently attract exploration, corresponding to jumps in the objective function. Like this; note how in this example the search is highly directed and focused, exploring some branches in much more details than others:

And the beautiful part? These shifts of focus and jumps in the target metric are interpretable; in effect, they are just code changes that we can examine and understand. The tree above corresponds to the following plot of metrics that can be easily annotated with specific novelties:

But the real magic happens when modern LLM intelligence supercharges the MCTS search. The system doesn't just randomly mutate code—it actively imports and synthesizes ideas from multiple sources:
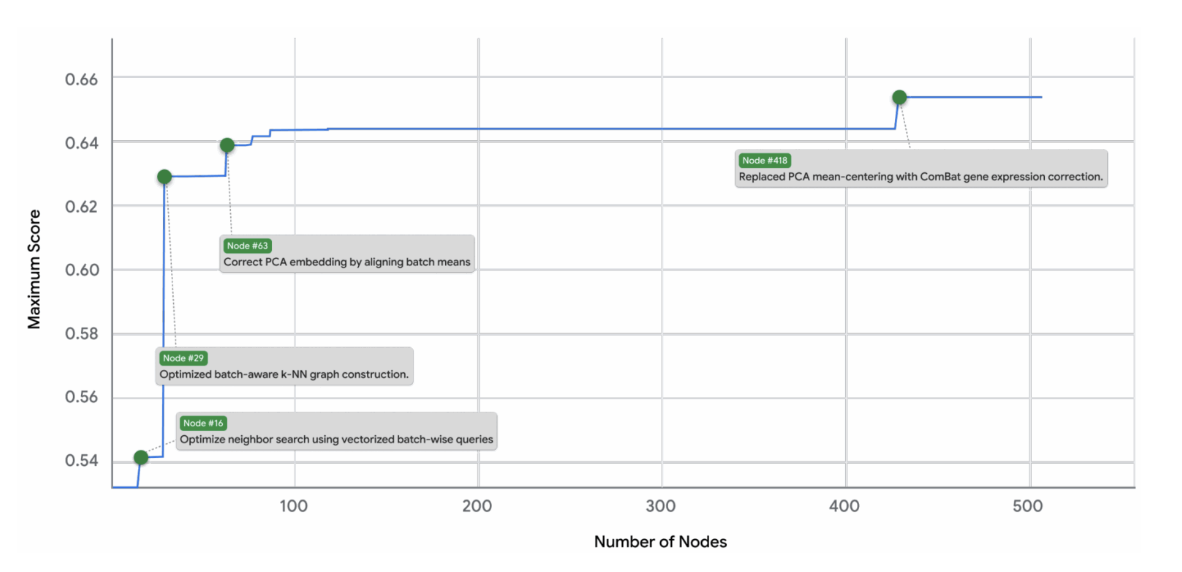
Consider a concrete example: you give the system a batch integration task for single-cell RNA sequencing data. It reads papers about ComBat, BBKNN, Harmony, and other methods, extracts key insights ("ComBat performs linear correction using empirical Bayes," "BBKNN balances batches in nearest-neighbor space"), then attempts to combine these ideas when generating new code.
The system's recombination capability—borrowed from genetic algorithms—is particularly elegant. Just as sexual reproduction mixes genes from two parents to potentially create superior offspring, the system takes two well-performing methods, asks an LLM to analyze their strengths and weaknesses, and generates hybrids that attempt to capture the best of both worlds.
This sounds primitive, but the results are striking. In that single-cell integration task, 24 out of 55 hybrids (nearly half!) outperformed both parent methods. One particularly elegant example combined:
The system created a hybrid that first applies ComBat for global correction, then uses BBKNN for fine-grained local balancing on the already-corrected PCA embeddings. This hybrid became the top method on the OpenProblems benchmark (Luecken et al., 2025), improving performance by ~14% over the original ComBat. In the table below, (TS) means that the method has been improved with tree search:

Could a human have invented this combination? Absolutely! In hindsight, it seems almost trivial. But ComBat and BBKNN were developed by different groups, published in different venues (biostatistics vs. bioinformatics), and typically used by different subcommunities. The global-then-local correction pattern exists in other domains but it had never been explicitly transferred to batch correction. The system found it not through insight but through systematic exploration; it tried dozens of combinations and noticed this one worked.
Think of it as having a tireless graduate student who has read all the literature, understood the core principles, and systematically combines them searching for optimal solutions. Perhaps the student does not have Einstein-level intuition yet, but she is extraordinarily diligent and can test hundreds of hypotheses overnight; as a result, she occasionally stumbles upon combinations that outperform what any human has tried before, and she is definitely smart enough to notice these successes and build on them.

Aygün et al. (2025) show that for the large and growing class of scorable scientific problems, “write the method” can be treated as search over code guided by an LLM that knows how to read and remix the literature. The results are strong not because the model hallucinates breakthroughs, but because the system systematically enumerates sensible alternatives at scale, preserves the rationale for each improvement, and lets the metric be the ultimate judge of performance. It is a pragmatic, engineering-style step toward the “AI co‑scientist” that many of us actually want: not a replacement, but a relentless, tireless colleague who keeps trying things while we sleep and leaves notes good enough that we can pick up where it left off.
There are many things to like in this work. First, the abstraction is crisp. Calling out “empirical software for scorable tasks” gives us a clean target class. It’s honest about what counts: not truth with a capital T, but “the metric you chose”. That honesty lets you build the right tool.
Second, human‑legible provenance: the breakthrough plots and idea descriptors are the audit trail we usually lose in AutoML‑style sweeps. You can point to the exact code change that moved the needle, and the notes are the right granularity for a human reviewer to understand and reuse.
Finally, it feels like a natural next step for the “AI co‑scientist” direction. It is not so much a one‑off demo that provided one striking result after spending millions on compute, but rather a workbench you could actually hand to a lab and say: “Here’s how to turn your scoring function into a code‑evolution engine.” The broader “AI co‑scientist” theme has been in the air all year, and this is perhaps the most practical implementation I’ve seen so far.
Naturally, there are problems. Goodhart’s law is still undefeated: when you optimize the scoreboard, you get exactly what the scoreboard measures, not the underlying intentions of the researchers. The paper is explicit about retrospective setup and allowed inputs (e.g., no external covariates in the COVID runs), but once you operationalize this in the wild, leakage and reward misspecification will inevitably appear.
Second, while the per‑edit cost can be small (simple candidates run in minutes), full searches can still add up. The authors’ choice of a Kaggle Playground “training ground” is smart precisely because it calibrates iteration speed and keeps you honest about leaderboard deltas, but for more involved problems the compute bills could still stack up high. For example, a typical search might involve 500-1000 code evaluations. For simple tasks (numerical integration), that's perhaps $100-500 in compute. For neural network training on moderate datasets, you're looking at $5,000-50,000. For large-scale problems requiring GPU clusters, costs become prohibitive. Still, plenty of research problems can be solved with relatively cheap experiments.
So what's my personal takeaway? This is genuinely inspiring: AI is automating routine work, but the routine itself has leveled up dramatically. Every scientist could have their own "code search assistant"—propose a novel idea, hack together a proof of concept, then hand it off with instructions to "squeeze every last drop of performance from this". Let's be honest: benchmark optimization currently consumes huge portions of scientists' time in applied fields, yet it's neither the most creative nor meaningful part of their work. The tedious parameter tuning, endless ablations, systematic architectural explorations are necessary, yes, but they hardly have inspired anyone to become a scientist.
The most interesting question for me is not whether this system can match human performance, but how humans and systems like this will collaborate in the near future. This system is not an autonomous researcher, and it suggests a tight loop where humans propose research directions, the system explores the space exhaustively, and humans interpret and generalize the discoveries. The system finds that ComBat + BBKNN works; the human realizes this suggests a general principle about global-local correction hierarchies.
On the other hand, we are watching the definition of "routine" creep ever upwards. Yes, these are still leaky abstractions—even basic scientific text written by LLMs requires careful checking and editing. But these systems keep improving, conquering new creative territories of scientific work with each iteration. This may raise uncomfortable questions for academia.
And here's the thing about science: we don't need five nines of reliability. Science isn't like running a production system where every failure costs money. If one run of the system produces a genuinely novel, effective algorithm, it doesn't matter if ten runs before it have led nowhere. That single success becomes a permanent contribution to human knowledge. The asymmetry is beautiful—failures are forgotten, but successes compound.
A scientist who can leverage tools like the system by Aygün et al. (2025) effectively might accomplish in months what previously took years—not by working harder, but by operating at a higher level of abstraction, focusing on ideas rather than implementation details. Here’s hoping that we human researchers will still be needed even in this brave new world.

Meta FAIR’s new Vision Language World Models (VLWM) take a fresh approach to AI planning: instead of predicting pixels or manipulating abstract vectors, they describe future states and actions in plain English. This makes plans interpretable, editable, and easier to trust, bridging the gap between perception and action. VLWM uses a pipeline of video-to-text compression (Tree of Captions), iterative refinement, and a critic model to evaluate alternative futures, achieving state-of-the-art results in visual planning benchmarks. While challenges remain—like text fidelity, dataset quality, and limits on fine-grained control—VLWM marks a major step toward human-AI collaborative planning.
Read post

The Hierarchical Reasoning Model (HRM) is a brain-inspired architecture that overcomes the depth limitations of current LLMs by reasoning in layers. Using two nested recurrent modules - fast, low-level processing and slower, high-level guidance, it achieves state-of-the-art results on complex reasoning benchmarks with only 27M parameters. HRM’s design enables adaptive computation, interpretable problem-solving steps, and emergent dimensional hierarchies similar to those seen in the brain. While tested mainly on structured puzzles, its efficiency and architectural innovation hint at a promising alternative to brute-force scaling.
Read post
Apolo turns your Data Center into an AI Powerhouse.

.svg)
.svg)


© 2025 Apolo Cloud Inc. All rights reserved.
