AI 2027 in 2026: One Year Left for Humanity?
This article evaluates AI development based on the "AI 2027" forecast, which predicted the rise of superintelligence. While quantitative metrics lag by about a third, qualitative predictions—such as the rapid shift toward autonomous agents and automated coding—remain highly accurate, bringing humanity closer to a technological singularity.
Preface

On May 4, 2026, Jack Clark, a co-founder of Anthropic, the company behind Claude, wrote a post that said, more or less, the following:
I'm writing this post because when I look at all the publicly available information I reluctantly come to the view that there's a likely chance (60%+) that no-human-involved AI R&D — an AI system powerful enough that it could plausibly autonomously build its own successor — happens by the end of 2028.
This is a big deal.
I don't know how to wrap my head around it.
Basically, the co-founder of a leading AI lab is saying that there's a better than even chance that within about two and a half years, we will have an AI capable of building a better version of itself, with no human in the loop. This idea—an AI improving AI, which improves AI faster, and so on—is what people mean by recursive self-improvement, or RSI. It is the mechanism that, if it actually takes off, could lead to an "intelligence explosion" and ultimately the technological singularity
This is more than just a personal opinion of Jack Clark's. Anthropic recently published an essay titled "When AI builds itself", where the company states that it already sees "early signs" of AI models speeding up the development of AI itself. We will come back to that essay and its amazing numbers below.
So today I want to reevaluate where we actually are on the road to RSI. It feels like the right moment, as I write this shortly after Anthropic's newest model, Claude Fable, became available to the public for a while (I had an opportunity to play with it, and frankly I was in awe) but was quickly taken down by orders of the US government. This is a story for another day, though.
For the baseline scenario, let me use a document that made a lot of noise last spring: AI 2027. It was written by a mix of AI insiders and professional forecasters, and, quite unusually for this genre, it wasn't afraid to put down specific dates. AI 2027 is a month-by-month scenario with dated milestones, predicted benchmark scores, and revenue and compute estimates. Here is its headline chart; but if you haven't read the forecast itself, go do that first, I'll wait; it's worth it:
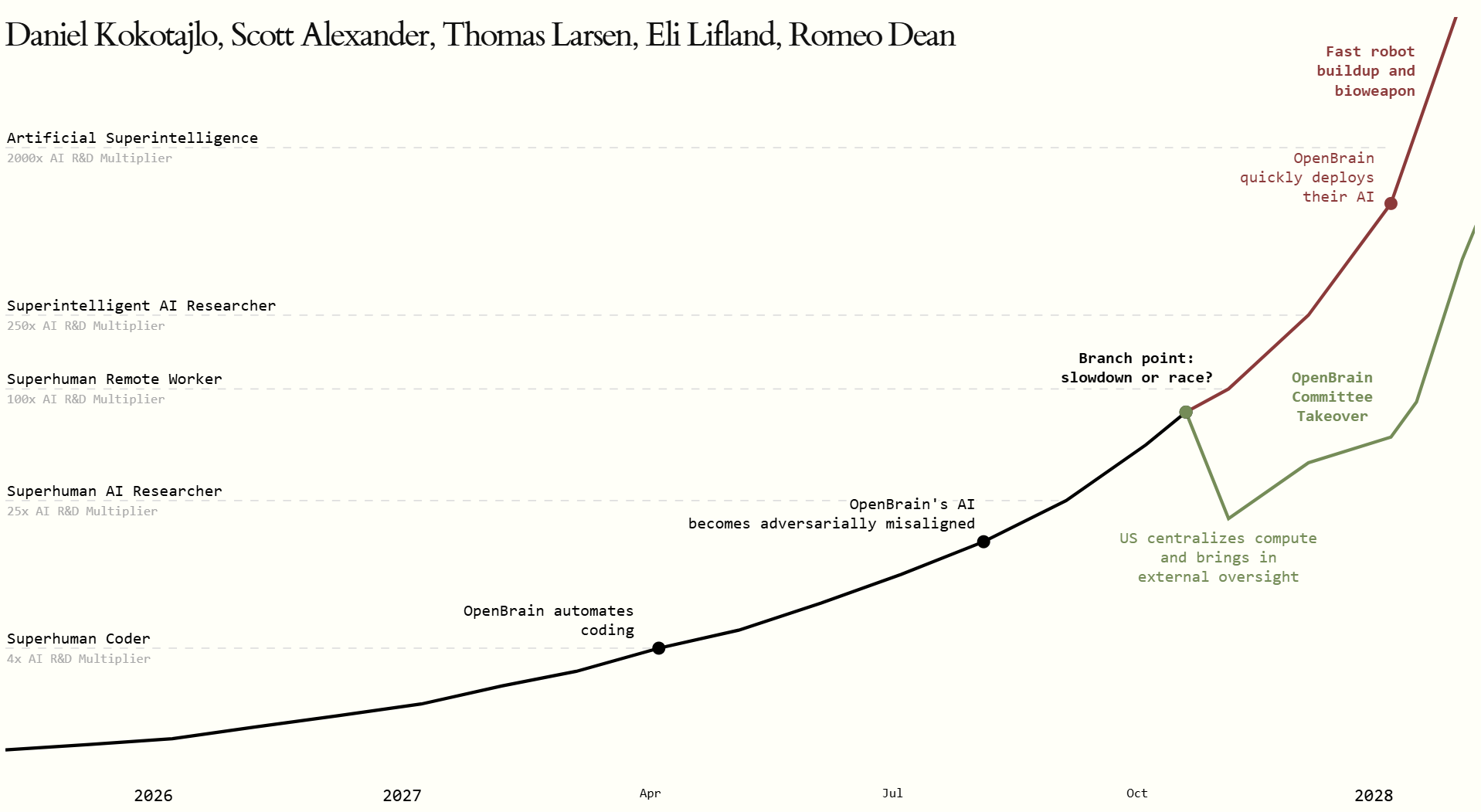
It's been a little over a year since AI 2027 came out. Let's check how the predictions are holding up.
There's a canonical way to do this: the site ai2027tracker.com, where enthusiasts compare the scenario's predictions against reality. Here's the tl;dr for the whole tracker:


But of course the green and red lights are not the interesting part. What's interesting is what's behind them: why some predictions came true and others didn't, what that tells us about the current pace of AI research, and, above all, whether any of this is bringing us closer to the moment when AI agents close the loop and head off into a singularity on their own.
Let's dig in!
AI 2027, in a bit more detail

AI 2027 was published on April 3, 2025 by the AI Futures Project: Daniel Kokotajlo, Scott Alexander (the best blogger alive; these days he writes Astral Codex Ten, but if you've never read him, start with the greatest hits of Slate Star Codex), Thomas Larsen, Eli Lifland, and Romeo Dean.
The key name here is Kokotajlo. He left OpenAI in 2024, publicly refusing to sign an agreement that would have stripped him of the right to criticize the company. And he has a track record: back in August 2021, before ChatGPT even existed, he wrote an essay called "What 2026 Looks Like" that described, with unprecedented accuracy, the shift from text generators to "chain-of-thought" reasoning and on to agents, roughly on the timeline that actually happened. You can call that a single lucky shot that proves nothing, but Kokotajlo is the only person who predicted how AI would unfold at a moment when almost nobody else was making concrete predictions at all, and the ones who were made far more sceptical predictions.
The scenario itself is essentially a work of fiction: a made-up leading lab called OpenBrain, a made-up Chinese competitor called DeepCent, and a month-by-month chain of agent models, from Agent-1 to Agent-5.
The overall plot goes like this. Up to a certain point, AI is a tool: it helps humans build AI. But at some point a model becomes good enough at AI research itself to do a large chunk of that work on its own. And that's when the feedback loop kicks in: AI speeds up AI development, the faster AI speeds it up even more, and so on.
AI 2027 flags two key thresholds along the way:
- a superhuman coder (SC) — a system that programs better than the best humans, and faster, and cheaper;
- a superhuman AI researcher (SAR) — one that's better than humans at the whole research job, not just the coding.
Between and beyond those two thresholds, progress accelerates because the models themselves are driving it; the finale is a transition to superintelligence (ASI) by the end of 2027. The scenario is also loaded with geopolitics—a US–China race, the (weak) security around stolen model weights, the problem of keeping an AI's goals aligned with ours—and it ends at a fork in the road: an unconstrained race leads to catastrophe, while a "slowdown" path leaves humanity a chance.
One important caveat tends to get lost in the public perception. The "2027" in the title is not the authors' median prediction. It's closer to the mode, the single most likely year under one particular model (there's a detailed note about this here). Since April 2024, the authors have pushed their dates back several times: in 2025 they decided they'd been too hasty and moved the forecast roughly a year and a half later, and by the end of 2025 they added a caveat that the authors' medians now sit somewhere in the 2028–2035 range.
According to the authors' own January write-up, Kokotajlo's median for reaching superintelligence (full ASI, not just a superhuman researcher) was 2031, and Lifland's was somewhere in the mid-2030s:

So no, AI 2027 should not be read as "we claim the singularity will happen in 2027". But honestly, for an event of this magnitude, a couple of years one way or the other hardly matters. The real claim is that superintelligence, and the singularity behind it, will arrive within our lifetimes, in the very foreseeable future.
Report card: two retrospectives

Around the scenario's first anniversary, two independent retrospectives appeared; it's good that there were two, because they look from different angles and still arrive at similar conclusions.
The first is from the authors themselves. On February 12, 2026, Kokotajlo and Lifland published "Grading AI 2027's 2025 Predictions," where they graded their own 2025 homework.
By their own assessment, the quantitative metrics ran at about 65% of the pace the scenario assumed. Both progress on a key coding benchmark (more on those soon) and the boost AI gives to AI research itself came in slower than expected.
After this admission, you might expect AI 2027 to be another "any day now, but not quite yet, and it'll always be that way" forecast. But look at the subtitle of their next update:

Moreover, most of the qualitative predictions did come true: OpenAI's annual revenue reached its projected ~\$18 billion and then some, and METR's "time horizon" metric (which I'll explain in detail below) ran almost exactly on schedule. And the big-picture call landed: agents really did arrive, and coding agents became a genuine working tool. So in the end the authors moved their prediction for *fully automating programming* into the "mid-2028 to mid-2030" window.
The second retrospective is the tracker we've already mentioned, ai2027tracker.com. Here, 53 concrete predictions were extracted from the scenario and each was given one of six statuses. As of summer 2026 the picture looks like this:
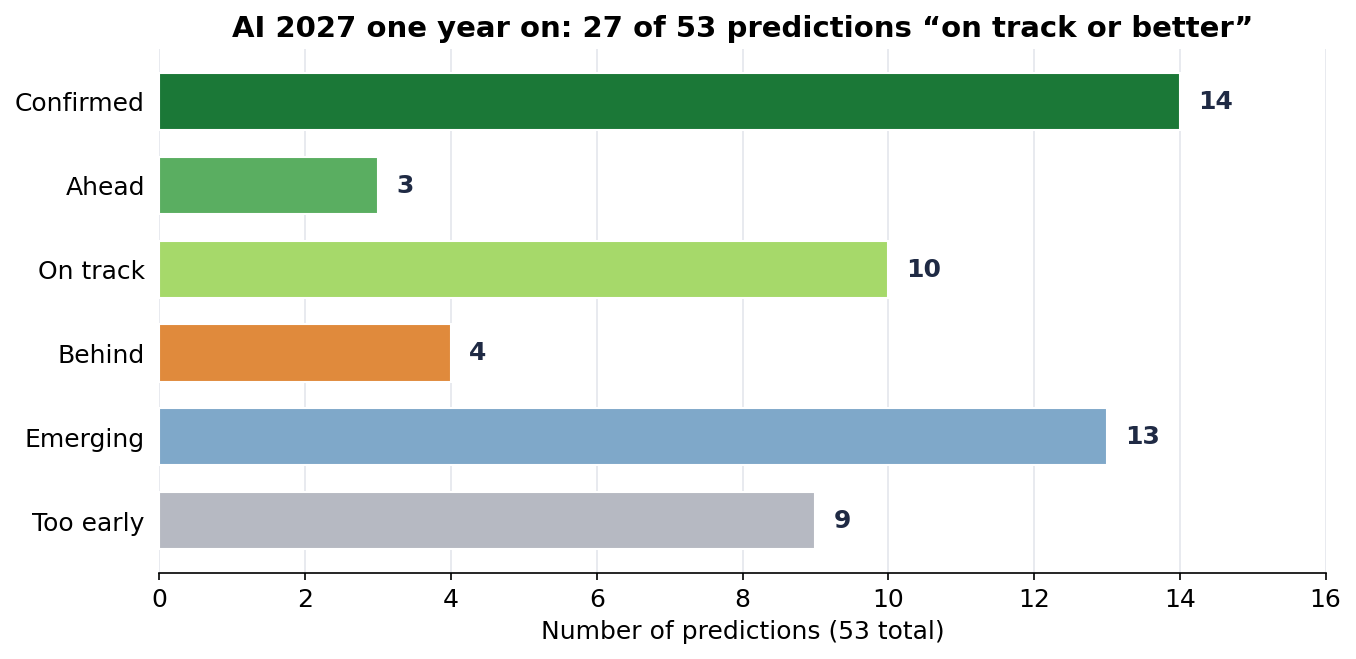
Both retrospectives broadly agree: reality is running at about two-thirds of the scenario's pace, maybe a touch more. What's curious is that the part landing confidently is the qualitative shape of the forecast: the shift to agents, to "AI workers", the investment boom, regulation falling behind. The part lagging is the numbers on benchmarks, which you'd normally expect to move ahead of the qualitative shifts, not behind them.
One prediction, by the way, came true well ahead of schedule, and in a rather unsettling way. Here's what AI 2027 says about the model "Agent-2", which the scenario expected to appear in early 2027:
OpenBrain presents Agent-2 to the government, including the National Security Council (NSC), the Department of Defense (DOD), and the U.S. AI Safety Institute (AISI)... Officials are most interested in its cyberwarfare capabilities: Agent-2 is "only" a little worse than the best human hackers, but thousands of copies can be run in parallel, searching for and exploiting weaknesses faster than defenders can respond...
As we all know, in reality almost all of this has already happened, with time to spare. As part of Project Glasswing, Anthropic set its frontier model Claude Mythos Preview loose on many open-source projects, and Mythos found numerous critical vulnerabilities fully autonomously, with no human involvement. There was a lot written about this, so let me refer you there, especially since I'm no expert in cybersecurity.
So here are a few of the headline predictions and how they're panning out:
- "Coding agents deliver real value by mid-2025" — true for a while now, though honestly agents only became broadly popular at the very end of 2025, not the middle;
- "85% on the SWE-bench Verified coding benchmark by mid-2025" — that turned out too optimistic; though AI 2027 isn't really about the exact numbers — I found this particular prediction buried in footnote 10;
- "Massive infrastructure investment in 2025–2026" — no argument there; we're marching toward a trillion dollars, Stargate is on track, and so on, and so forth;
- "Autonomous zero-day discovery by Agent-2 in early 2027" — this came true much faster than predicted;
- "Safety and regulation lag behind capabilities" — this too seems indisputable; Mythos awoke the US administration, and there's a fresh executive order on frontier AI safety, but it's all still soft and reactive rather than proactive (again, this is a topic for another day).
The two most interesting predictions for us today are "superhuman coder in 2027" and "transition to ASI by the end of 2027 via autoresearch". It's too early to grade them, but let's talk about where we stand.
The autonomy horizon: the one chart that matters

To talk about pace seriously, you need a metric. The trouble is that classic benchmarks work badly here. They saturate, that is, models cluster close to 100% and the metric stops telling models apart; even more importantly, "90% on benchmark X" usually says very little about what a model can actually do that's useful in the real world.
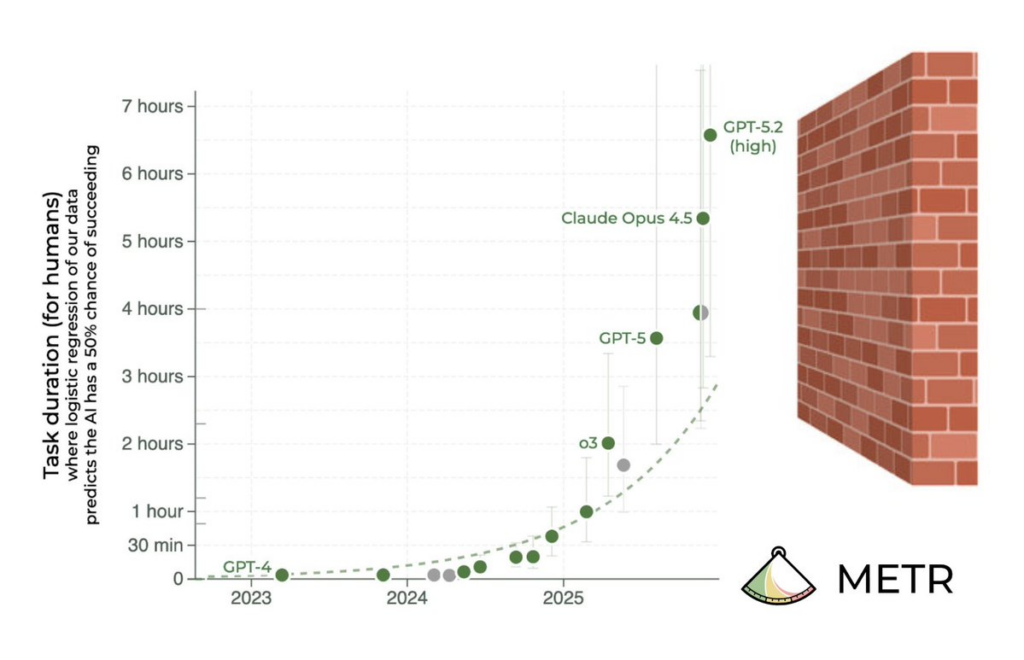
An organization called METR (Model Evaluation and Threat Research) proposed a metric that has long since become the single most important chart in this whole debate. Their idea was to take a set of tasks—METR uses about 230 tasks in programming, ML engineering, and cybersecurity—and for each one, measure how long it takes a human expert to do it. Then define a model's time horizon as the human task length at which the model succeeds with 50% probability. Simply speaking, if a model's time horizon is one hour, it can (not really reliably, but often) handle tasks that take a human about an hour.
The beauty of this metric is that it's measured in natural units of human time rather than percentages on some test. And METR's data shows a confident exponential climb:
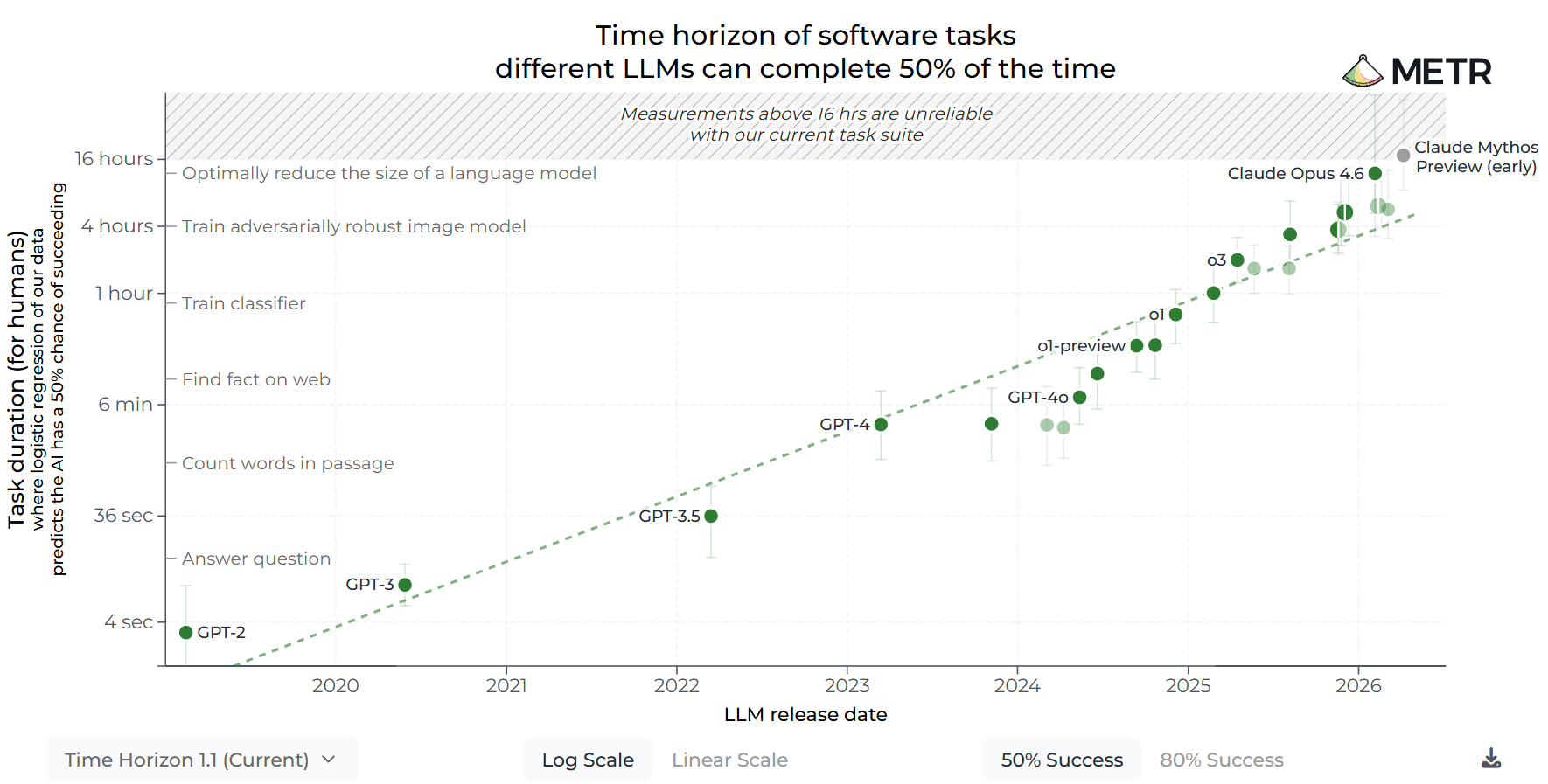
The technical way to say it is that the time horizon doubles every so often, and the key number is that doubling time. In METR's original study (March 2025), over the 2019–2025 window it was about 7 months.
In January 2026, METR released an update called Time Horizon 1.1 (that's what's in the charts here): they expanded the task set from 170 to 228 and roughly doubled the share of tasks longer than eight hours. The recomputed numbers showed a doubling roughly every 6.5 months over the whole period, every ~4.3 months since 2023, and every ~3 months since 2024. In other words, the curve isn't just exponential, it's actually superexponential, that is, the exponent itself is speeding up. (Granted, the very early part, where we were timing tasks in seconds, doesn't mean much.)
In absolute terms: as of February 2026, Claude Opus 4.6 topped out at a time horizon of about 12 hours, and that same Mythos Preview hit the ceiling of what METR can reliably measure — there simply aren't longer tasks in the benchmark, and at that scale it gets hard to even estimate "human time" anymore.
When I saw this chart a year ago, I thought: hmm, there aren't that many doublings left in it. A human can't work 16, or even 8, hours straight at full concentration: we need to go to sleep and rest, which essentially resets our context.
I still think that's true, but as you can see, the doubling hasn't slowed down at all on the way up to a full work-day, and it looks like the horizons will keep doubling for a while. An AI that can autonomously handle week-long and month-long tasks is already almost the literal definition of a "superhuman coder".
There is an important caveat, of course. Those multi-hour results are about a 50% success rate. "Succeeds half the time on an hour-long task" is indeed very impressive, but it's still not an autonomous system, just a very good assistant whose output you have to check carefully (and as you all know, this is exactly where we are now: you can use AI agents very productively but you can't quite trust them yet, verification is paramount).
METR also has a chart for the 80% success rate, and it looks exactly the same, just lagging the 50% line by two or three doublings — that is, by half a year to a year:

What I'd really love to see is the chart for 99%, or for whatever success rate a real human achieves. What is that rate, by the way? I genuinely have no idea what is the probability that a professional programmer successfully finishes a task that should take them a day; and the word "finishes" would itself need a careful definition...
The reliability problem: from benchmark to real work

METR also has some negative results. In July 2025 they ran a randomized controlled trial: they took experienced maintainers of open-source projects and had them solve tasks in their own repositories, with half allowed to use AI tools and half not. The result was surprising even to the sceptics: with AI, the developers took 19% longer, that is, help from AI slowed them down. Morevoer, even after the fact the participants were convinced the AI had sped them up.
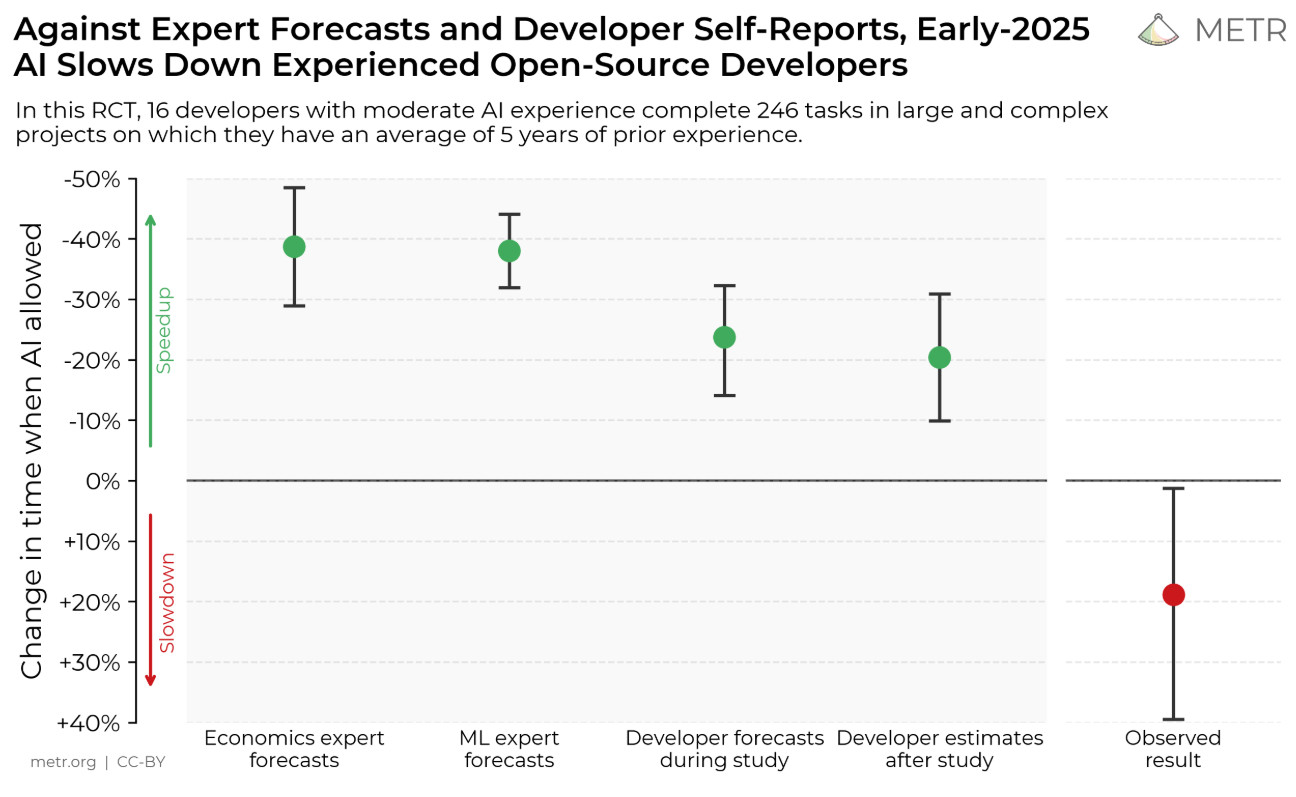
This experiment still gets cited as proof that "AI is useless". But even without reading the fine print, it's clearly about "AI as of mid-2025" — and a year has passed since.
In February 2026, METR revisited the experiment: 57 developers again solved tasks in their repos, half with AI and half without. The numbers show that by early 2026, people felt much more speedup from AI usagg than a year before, and the actual slowdown had nearly vanished:
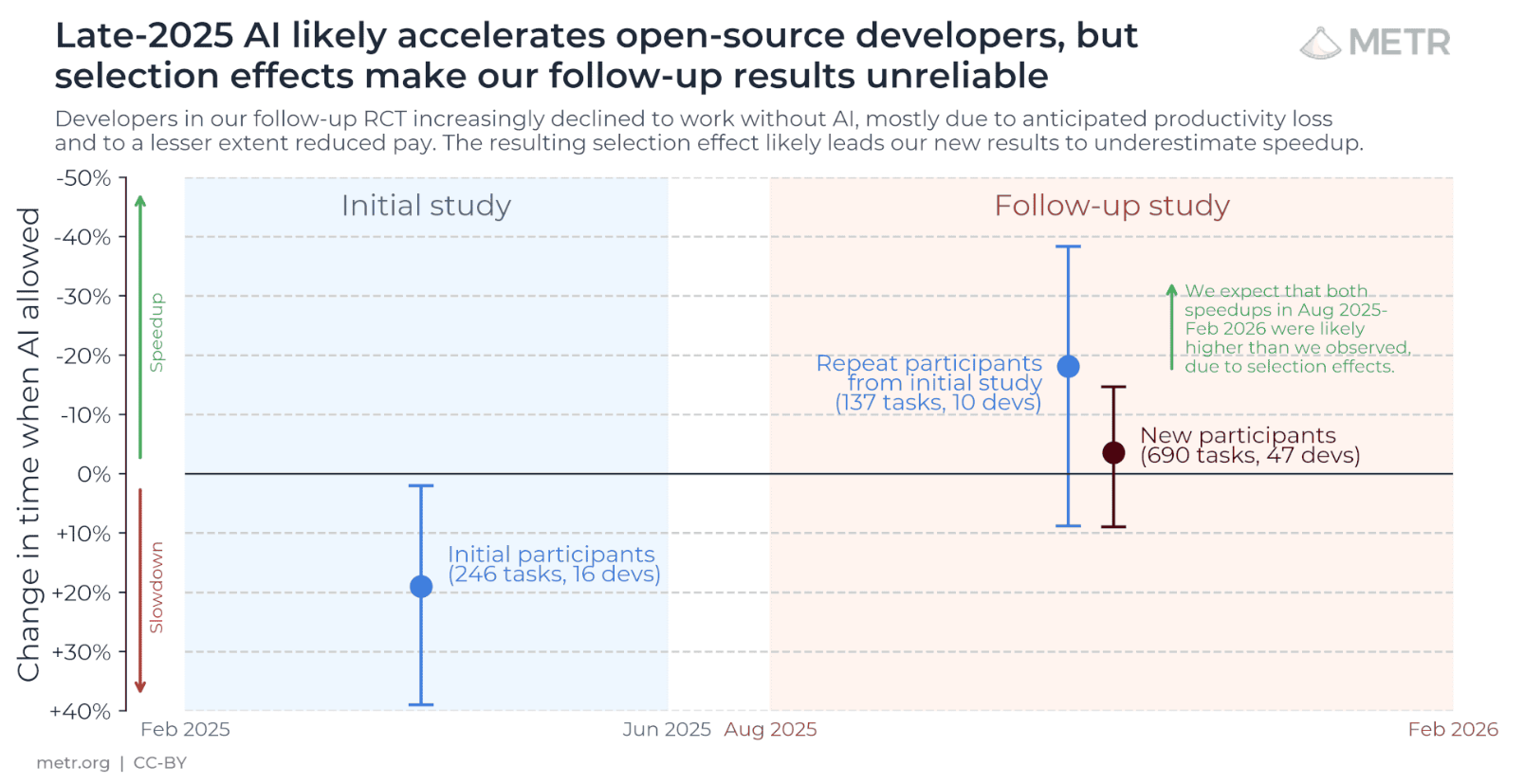
But the funniest, and the most telling, thing about this study is that the very ubiquity of AI assistants is now sabotaging the ability to run the study at all. The people AI helps most are increasingly impossible to recruit, as a growing share of developers say they "wouldn't agree to do even half their work without AI". Worse, 30% to 50% of participants admitted they deliberately didn't bring certain tasks into the experiment because they didn't want to do them without AI. So the very tasks where AI helps most are systematically filtered out of the sample.

That's why METR honestly calls its own estimate an "unreliable signal", and it is at best a lower bound on the true effect.
In another study (March 2026), METR took AI-generated pull requests that pass the SWE-bench Verified tests and handed them to real maintainers for review. It turned out that about half of those PRs wouldn't actually be accepted:
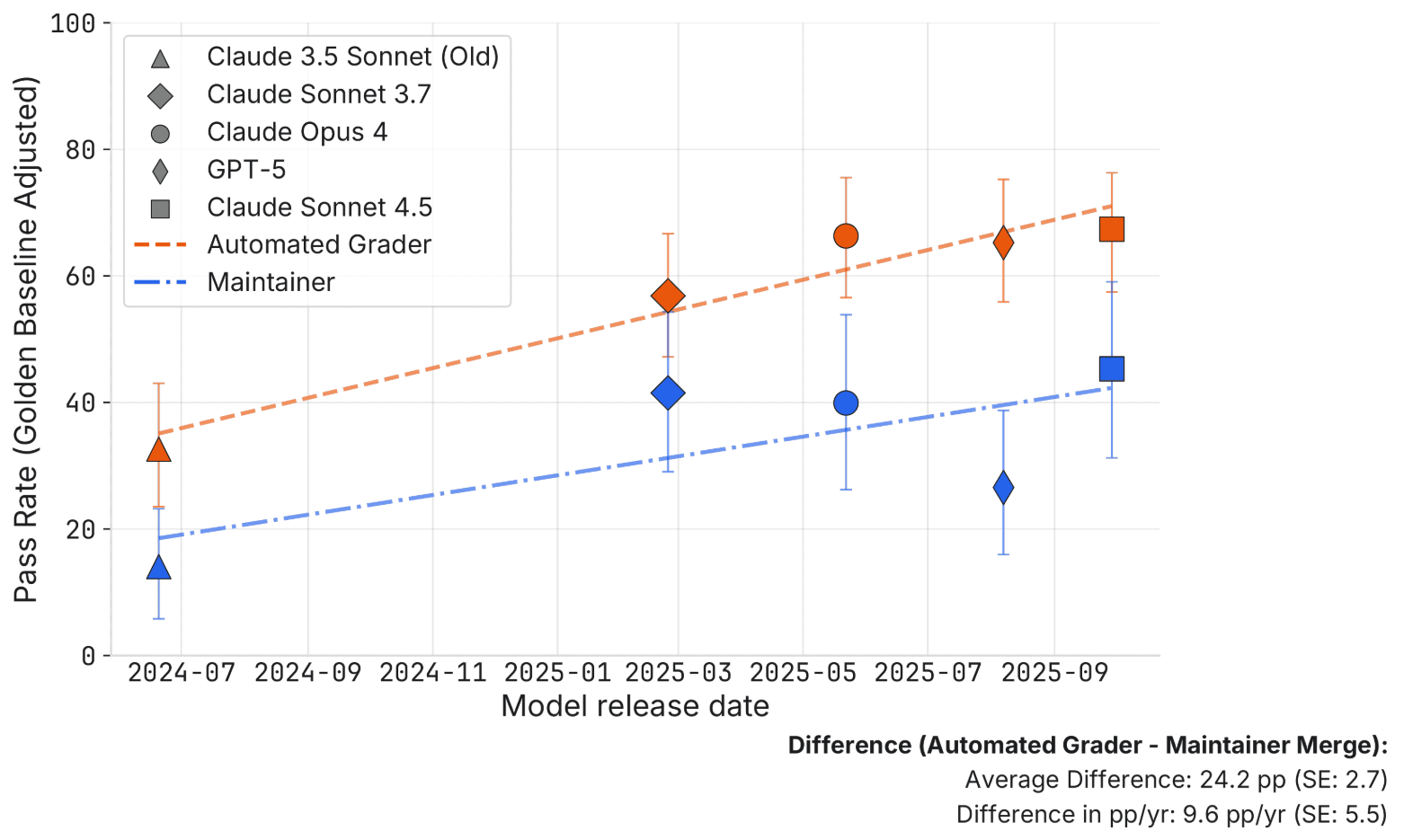
In other words, there's also a gap between "passes the tests" and "is a genuine engineering contribution," and this gap has not been closed.
The underlying arithmetic here is simple: if an agent has to complete a task consisting of many steps in a row, and each step succeeds independently with some probability less than one, the chance of getting the whole thing right shrinks fast. Multiply enough numbers below one together and you get something tiny:
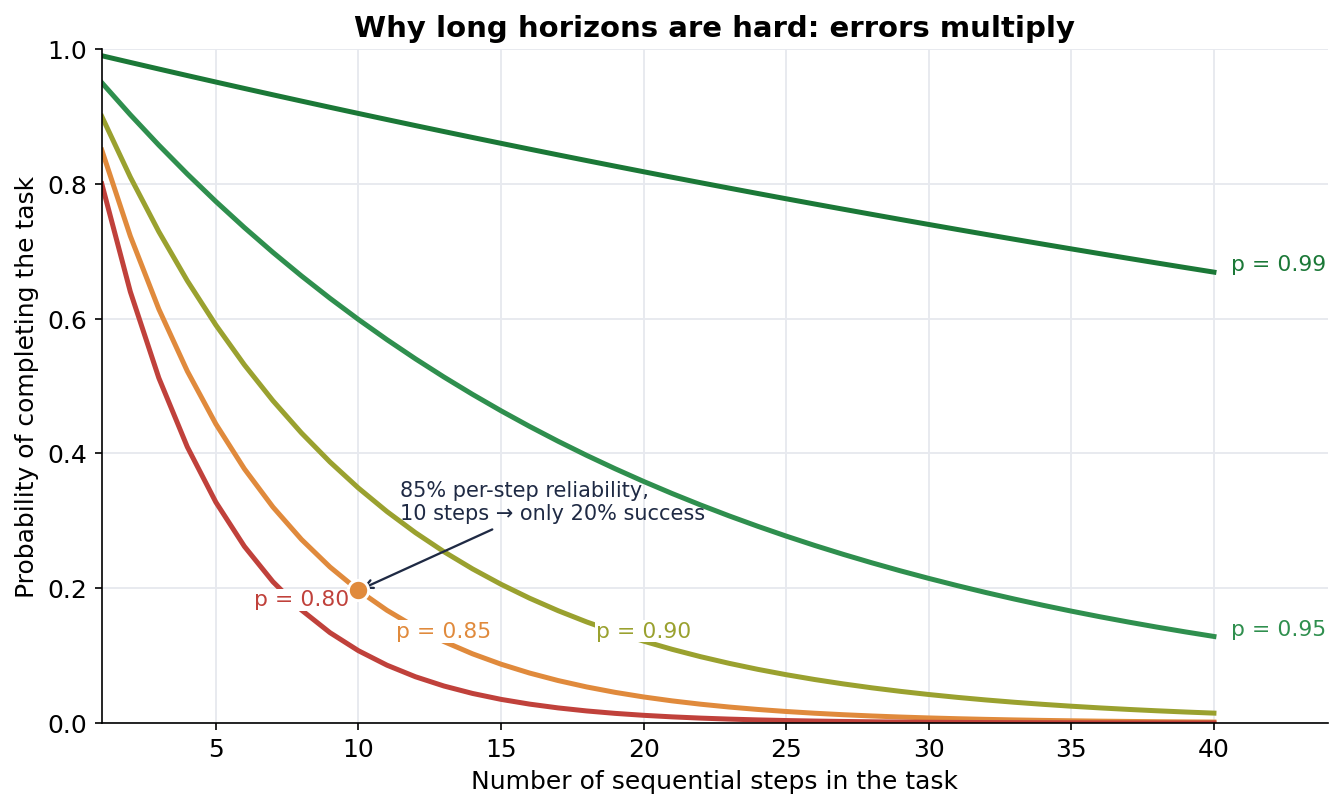
For example, a fresh benchmark called APEX-Agents from Mercor (480 tasks drawn from the working lives of investment bankers, consultants, and lawyers) found that the best models finish only about 23–24% of tasks on the first try (GPT-5.2 at 23%, Gemini 3 Flash at 24%); even with eight attempts, the best result is around 40%.
And a February paper on "Canonical Path Deviation" (Lee, 2026) shows that one bad tool call raises the probability that the next call is also bad by about 22.7 percentage points. So the errors don't just multiply, they correlate, and the agent tends to spiral.
As a result, while the METR horizon curve looks very promising, it isn't yet a finished proof or a sign that the singularity has already arrived. There still remains a sizable gap with reality. It will surely be closed soon if the current exponentials continue — but that hasn't happened yet, and it isn't guaranteed.
Autonomy and autoresearch: the benchmarks

Now to the question I personally care about most: how close are we to autoresearch, that is, to AI models running research on their own, and above all research into AI itself?
In this section let's walk through the benchmarks. I've cautioned many times that benchmarks don't perfectly match reality, but people do try to make them show something.
The bottom rung is the famous SWE-bench Verified: real GitHub bugs that have to be fixed so that a set of (hidden) tests passes. A year ago this was the main exam for coding agents; today it's essentially passed. The top of the official leaderboard sits around 76%:
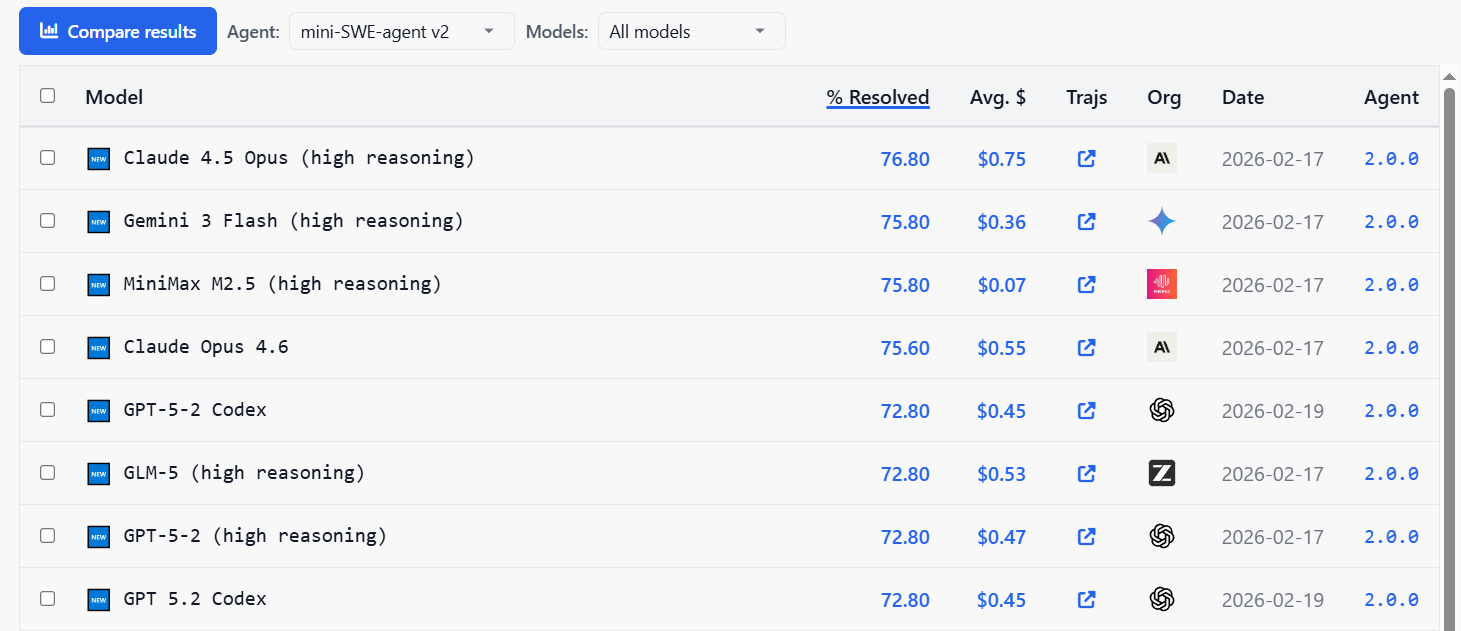
The labs' own "system cards" for their latest models claim above 80%, and here and there we see even numbers like 90–95% (though that smells more like marketing).
Worse, in February 2026 OpenAI itself stopped using SWE-bench Verified: their audit of the 138 hardest tasks (the ones o3 couldn't solve consistently even across 64 attempts) found that more than half of them simply have broken tests, that is, they reject functionally correct solutions! On top of that, there was evidence that the solutions had leaked into the training data of all the leading models. So you can consider this benchmark finished.
There are harder versions: SWE-bench Pro, with standardized scaffolding, where the same models drop by tens of points, and SWE-rebench, which continuously mixes in fresh issues to fight data leakage. But on the whole, "fix a labeled bug" looks like a stage that we have passed.
One rung up is MLE-bench from OpenAI: 75 real Kaggle competitions, where the agent goes through the whole ML engineering cycle (prepare the data, train a model, iterate) and is scored on Kaggle's human medal scale. Here too, almost everything has changed in the last year and a half: in the original 2024 paper the best model earned a medal in about 17% of competitions, while on today's leaderboard top agents earn a medal in roughly 62–64%. "AI agent as a solid ML engineer" is becoming reality.
Higher still is RE-Bench from METR: seven open-ended research-engineering tasks, with a direct comparison against dozens of human experts.

The most telling result of the original study wasn't an absolute number but the shape of the curve: given a 2-hour budget, the agents easily beat the experts (agents are faster, cheaper, and parallelize nicely), but given 8 or 32 hours, humans pulled clearly ahead because agents in 2024 just didn't have the stamina for long autonomous research.
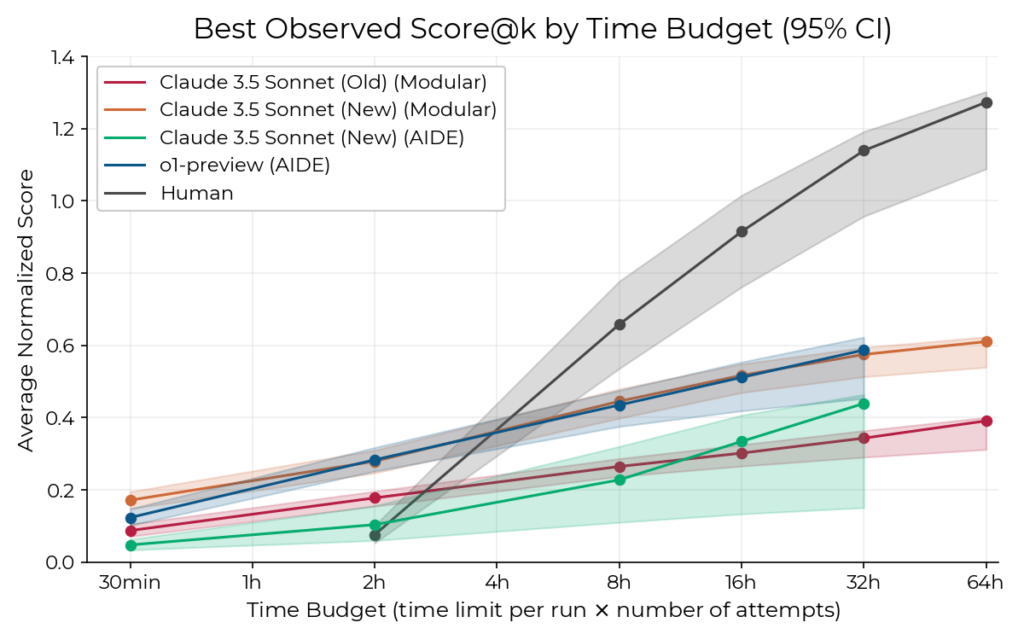
But by 2026 the frontier models grew so much that this rung, like METR's whole R&D arsenal, has largely saturated: Opus 4.6 handles more than 80% of the tasks in METR's set, and the crossover point where humans still held the lead has to be sought at ever longer horizons (hence MirrorCode, with tasks measured in weeks). Roughly speaking, the agents have already won the sprint, and the argument has moved to marathon distances.
The next step up the ladder is PaperBench, also from OpenAI (Starace et al., 2025): reproduce 20 papers from ICML 2024 from scratch (thousands of checkable sub-tasks); this means that the agent needs to understand the contribution, write the codebase, run the experiments, and get the same numbers.

A year ago the results here were around 20%, and there's no real leaderboard as such; I am curious how Claude Mythos would do now, though.
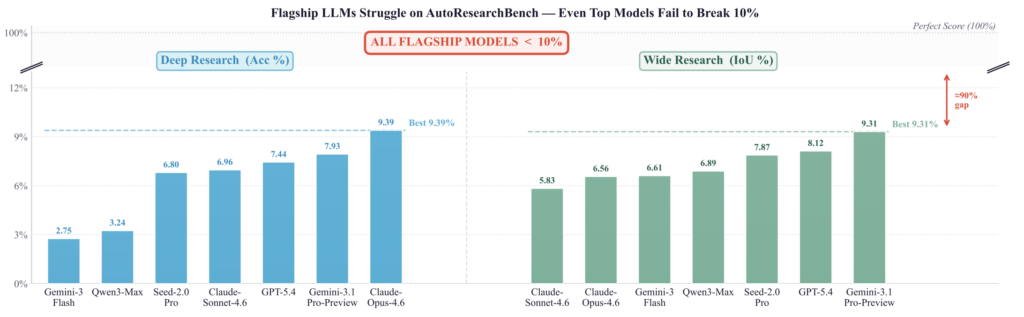
And finally, the top rung is AutoResearchBench (April 2026), where the task isn't to reproduce a single paper but to navigate the literature: track down the paper you need through a multi-step search across all of arXiv (millions of papers), or assemble every paper that meets some condition.

This is very close to the real work of a researcher, and here the models, which already handle ordinary web-surfing benchmarks like BrowseComp well, fall apart: the frontier sits at around 9%.
These aren't all the benchmarks, of course, but they're a fairly representative slice.
In short, the process is in motion as usual: benchmarks saturate, people invent new benchmarks. And the verdict, for now, is this: on the most realistic open-ended tasks, humans are still needed. Autoresearch as a "ready-made autonomous scientific workforce" has not arrived yet. But the first steps have been taken; let's talk more about that.
Autonomy and autoresearch: the positive results

Autoresearch hasn't arrived yet but, by God, it is arriving! In the areas where you can build a fast and honest automatic verifier, agentic systems are already making real discoveries.
Last month we had an especially exciting piece of news. On May 20, 2026, OpenAI announced that one of its internal reasoning models had disproved Erdős's unit-distance conjecture, a problem almost eighty years old that the world's leading mathematicians genuinely thought hard about; maybe at some point I will write a detailed post about it.
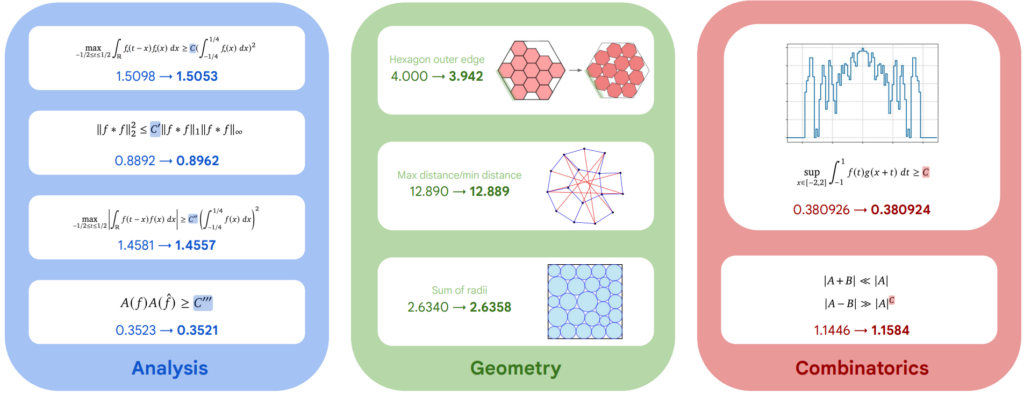
But this is far from a one-off. Recall AlphaEvolve from DeepMind, now a year old: a pairing of an LLM with evolutionary search, where the model proposes changes to code and a verifier runs them and keeps the best. Back then, AlphaEvolve improved the scheduling of Google's data centers, helped with chip design, found new matrix-multiplication algorithms, and, most elegantly, sped up the training of the very model it runs on by inventing new kernel optimizations. Some mathematical results moved forward too:
Google's AI Co-Scientist made the news last spring, but now there's also an AI Co-Mathematician from the same DeepMind (Zheng et al., May 2026). There's nothing interesting in its architecture at all:
But it scored 48% on FrontierMath Tier 4 — a new record.
I should add a caveat right away, though: Epoch recently reported the following:

...in short, even the best benchmarks turn out to be not without sin.
Or here's another example: METR's April note on NanoGPT. NanoGPT is one of my favorite illustrations of how algorithmic progress actually moves: over two years, the training of a small GPT was sped up from 45 minutes to about a minute and a half: a 30× speedup, on the same hardware, naturally.
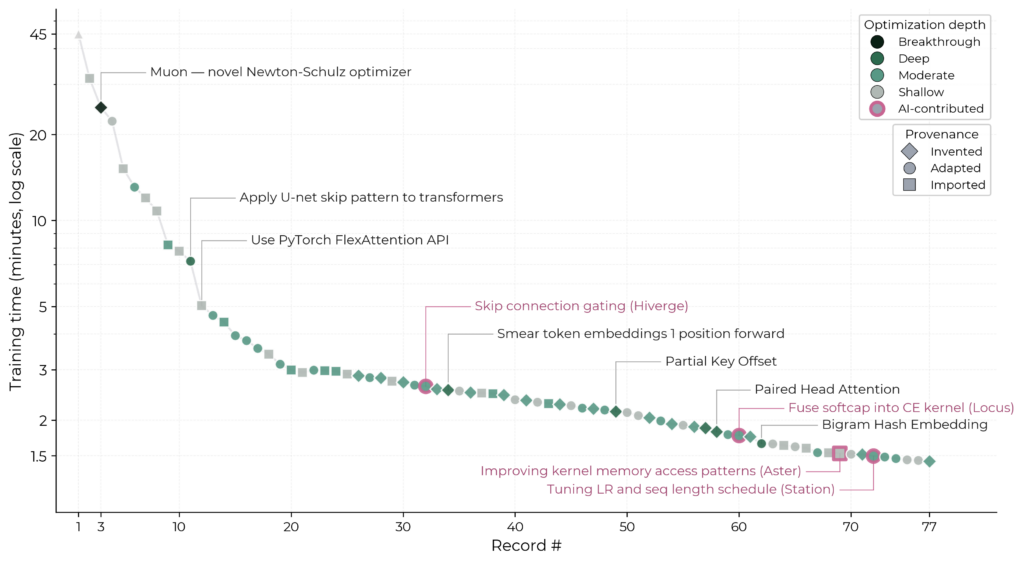
Here's the key part: Manish Shetty of METR broke that speedup down into components. Imported ideas (borrowed from other people's work) accounted for 6.7×, adapted ideas for 3.0×, and ideas invented from scratch for only 1.6×. And the contribution of AI agents themselves to the records (there have already been four auto-improvements) turned out to be shallow, usually amounting to importing and adapting. (Though, as an aside, in the big picture a lot of small ideas are just as important as a single big one.)
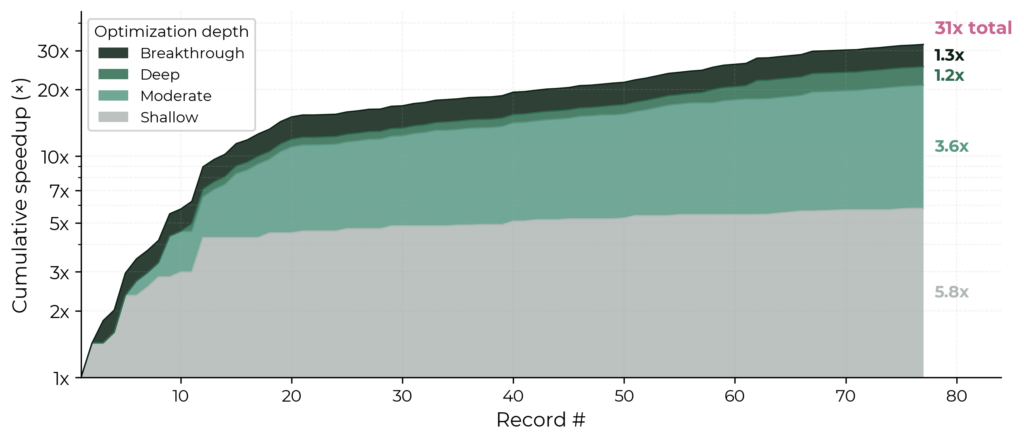
A lot of this makes it look like the successes are still limited, that human scientists won't lose their jobs anytime soon, and that progress looks "ordinary" rather than "revolutionary" or "singular".
But... have you actually tried it yourself? Have you really setClaude Code with Opus 4.8 Max (or the just-released Fable) and GPT-5.5 Pro free on your own research problems?
Yes, yes, I just spent several sections telling you, numbers in hand, that you can't trust subjective impressions. But I tried it anyway; I put my fingers in the wounds and now I believe. Sure, the models and the agents built on them can still make mistakes, and they make them fairly often. Sure, you can't yet ask one to prove the Riemann hypothesis, wait a week, and get a proof.
But the degree of autonomy and the level of intelligence in systems available even to ordinary users right now are astonishing. And the mistakes they make can often be caught and fixed by the same models (or by other models). And as for the difference between "needs checking" and "needs inventing" — well, there's no need to explain that to anyone who's heard of P versus NP.
Infrastructure and timelines

There's also a part of AI 2027 that is coming true without any discount, and in places ahead of schedule: the infrastructure.
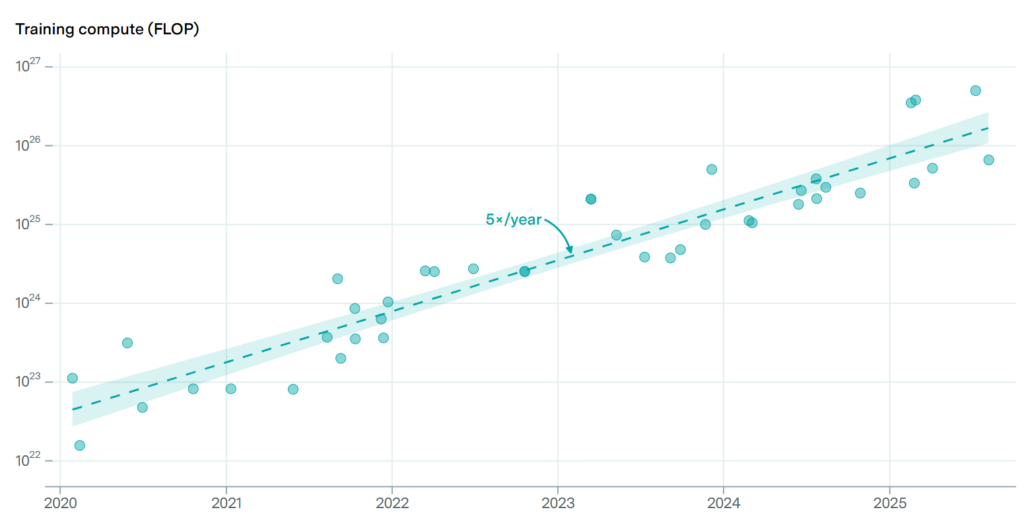
According to Epoch AI, the computing power used to train frontier models has been growing about 5× per year since 2020, while the dollar cost of a single frontier training run doubles roughly every 7 months:
Stanford researchers estimate that private AI investment reached hundreds of billions of dollars in 2025, though it's still very uneven across countries:
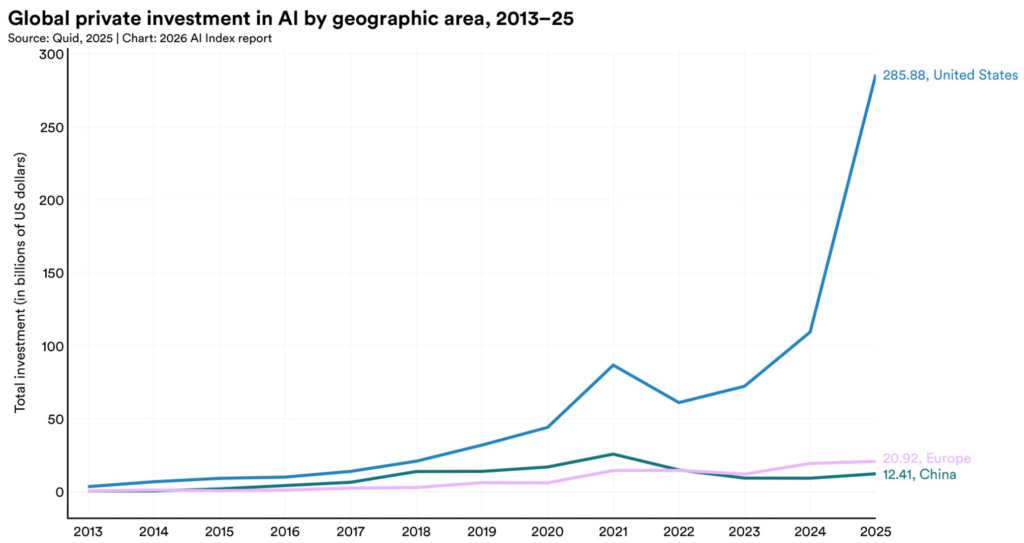
The same Epoch AI publishes a chart of the cost and power of leading data centers. Right now the record holder is Anthropic–Amazon's New Carlisle at 1.1 GW, which cost $35 billion — but Fairwater Wisconsin will be three times more powerful electrically and eight times more powerful in compute:
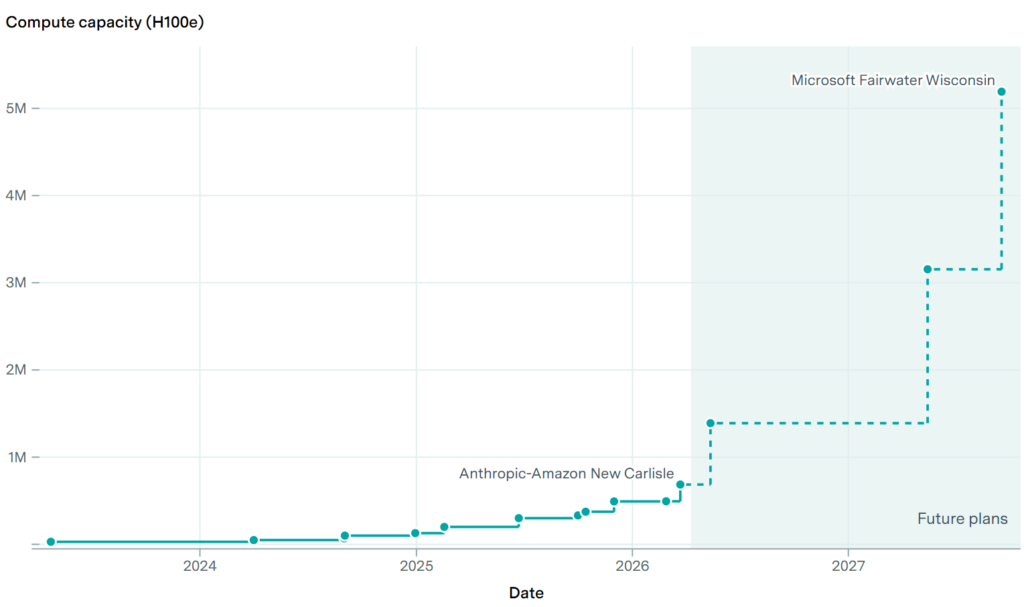
A story of its own is Stargate. The project was announced in January 2025 with plans for $500 billion in investments and about 10 GW of capacity over four years, by 2029. That 10 GW is the total capacity of the whole program across seven sites by the end of the decade, which is why it doesn't appear on the chart above — it's not just a single data center. But as of mid-2026, Stargate has already contracted about 7 GW of planned capacity, and OpenAI promises to reach the full 10 GW ahead of schedule.
In parallel, the second half of 2026 brings NVIDIA's next-generation Vera Rubin GPUs and the start of mass production of OpenAI's own accelerator, the XPU, built with Broadcom on TSMC's 3nm process.
In short, the race for capacity is running ahead of schedule, and half a trillion dollars invested is a powerful incentive to find something to fill all those data centers with. It looks like compute shouldn't be the thing that bottlenecks the singularity.
But there's a flip side, of course. ML experiments need not just ideas but those very computations. You can speed up and improve idea-generation all you like, but if reaching RSI requires testing every good idea by training an LLM of true frontier size, then the bottleneck becomes not intelligence but compute, no matter how many Stargates you fire up. See, for example, the paper "Will Compute Bottlenecks Prevent an Intelligence Explosion?"
Will LLM agents launch the singularity?

And so we arrive at the main question. Will LLM agents set off the recursive self-improvement that would send us into a singularity? Formally, for that to happen the slope of those exponential curves has to keep increasing over time — the gap between doublings has to keep shrinking.
I'm very fond of this picture on the subject, a reply to a post by Gary Marcus that didn't age well:
By the way, as you can see, the picture is already rather old, and the exponentials haven't slowed since; if anything, the opposite.
But the exponentials aren't really the point; after all, there are no laws of nature here, it's just empirical measurement of progress. What matters is that AI has to become good enough at AI research for the research loop to close on itself. Does it look like that will happen?
I think it does.
It looks like the first turns of that loop are already grinding into motion before our eyes, and the best document about it is that same Anthropic essay, "When AI builds itself" that I opened with. Look at what's happening at the frontier.
As of May 2026, Claude writes more than 80% of the new code at Anthropic (a year ago it was a few percent):
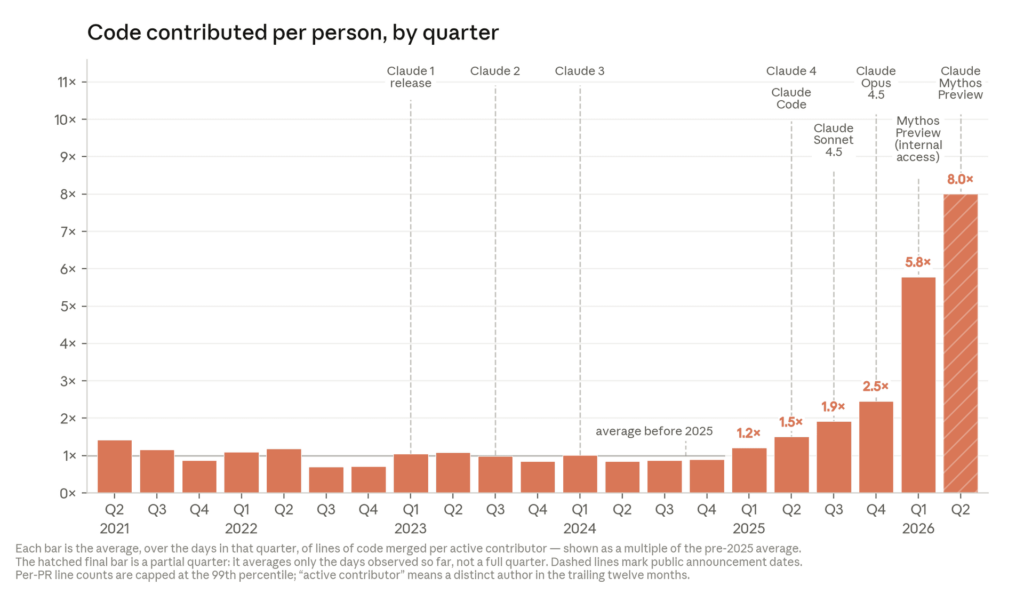
And Claude Code (which is, naturally, what the developers mostly use) keeps steadily improving. "Session success" below is a proxy metric, judged by how much had to be fixed after a request to Claude Code:
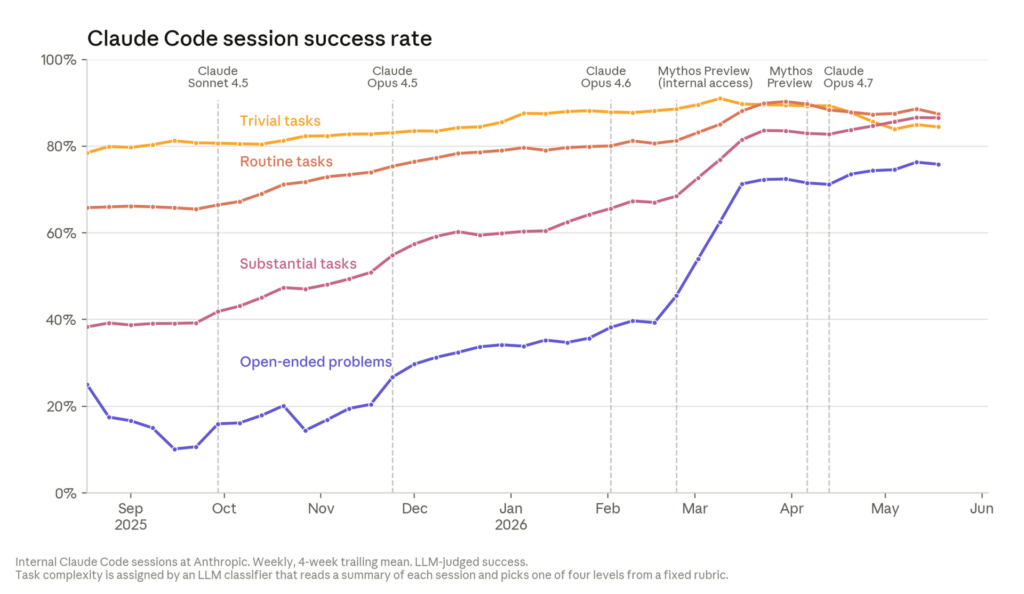
Anthropic has an internal test: optimizing the training code for an ML model. A year ago Claude Opus 4 could get about a 3× speedup over the baseline. Now Claude Mythos Preview gets about 52× (a human professional, by Anthropic's estimate, can manage roughly 4× in a working day). As they put it in the post, over the year "Claude has gone from super helpful to superhuman"...
Here are a couple more quotes from Anthropic, each of which I'd personally sign my name under:

OpenAI, by the way, also laid out a roadmap at some point and is moving toward "AI research interns" in 2026 and full-blown automatic AI researchers in 2028.
But there is another side: that same Anthropic essay ends by stressing that RSI is by no means a foregone conclusion. New bottlenecks can show up. For instance, once generating code stopped being the bottleneck, human review became one. In research, the bottleneck right now is that notorious "taste": in this case, research taste, the overall strategy of which direction to go.
What exactly is missing

Other researchers have very specific opinions on what's still missing before we get real AI researchers. Andrej Karpathy, for instance, in his conversation with Dwarkesh Patel (October 2025), said that "AGI is still a decade away", and that it'll be "the decade of agents", not "the year of agents". For Karpathy, what's missing is continual learning and multimodality.
Personally, I think there are no satisfactory answers yet to the following questions.
Memory and continual learning. An agent that can't reliably learn from its own experience can't accumulate expertise the way a living researcher does over years. We have reviewed the state of memory in LLM agents in a recent long post, and the very fact that memory is still a research frontier, not just an engineering problem, speaks for itself.
Long-horizon reliability. That same arithmetic of compounding errors. It's far from obvious that this gets cured by more scaling. Though it might, of course: the history of deep learning has long since trained us not to bet against scaling.
Sample efficiency. A human becomes a real researcher on a vanishingly small fraction of the data a model has seen; and running reinforcement learning on the actual research process (rather than on textbook problems) is unlikely to be feasible.
Taste and problem selection. The ability to understand which question matters. No benchmark measures this, because in a benchmark the task has already been chosen for you. Inventing new ideas is still almost entirely on humans... Although I should qualify that: modern models are already pretty good at generating ideas — it's that humans still have to choose among the generated ones.
World models and grounding. Agents still lack a reliable, updatable model of the systems they act in. That's a big topic of its own, which I hope to come back to someday.
None of these is a proven, insurmountable wall, but none of them has clearly been solved either. And the strong form of AI 2027 quietly assumes they'll all fall on schedule, and more or less simultaneously.
Conclusion

I won't, of course, name any dates. I won't even try to define what "real RSI" or a "real autonomous AI researcher" would be. But I can say a few things.
Almost certainly, coding and research agents will become routine, permanent participants in software development, running experiments, surveying the literature, parts of ML engineering, proving theorems... This is essentially already happening.
Most likely, agents are already noticeably accelerating frontier AI research inside the labs, and will accelerate it more — for now as human-directed teams of agents rather than as autonomous scientists.
Most likely, a real "superhuman coder" in the AI 2027 sense will indeed appear by 2027–2028. It may be narrower and more specialized than the scenario's authors imagined, but I think it'll be here.
But most likely it will not be a transition to RSI, and ASI behind it, by the end of 2027 through a closed autoresearch loop. Not that it's impossible, but it looks like we're on a slower timeline after all.
Still, I never tire of repeating: "not that soon" doesn't mean "never", and it doesn't even mean "not soon"! People have short memories: the moment an AI proves a new theorem, they'll immediately say the theorem "wasn't that hard" or was "uniquely suited to an AI proof"...
So every time I talk about recent AI successes, I try to stress how gigantic this progress is over a tiny, negligible span of time. Four years ago, LLMs struggled with elementary school math problems (this is a picture from Wei et al., 2022, the paper that introduced the chain-of-thought technique):
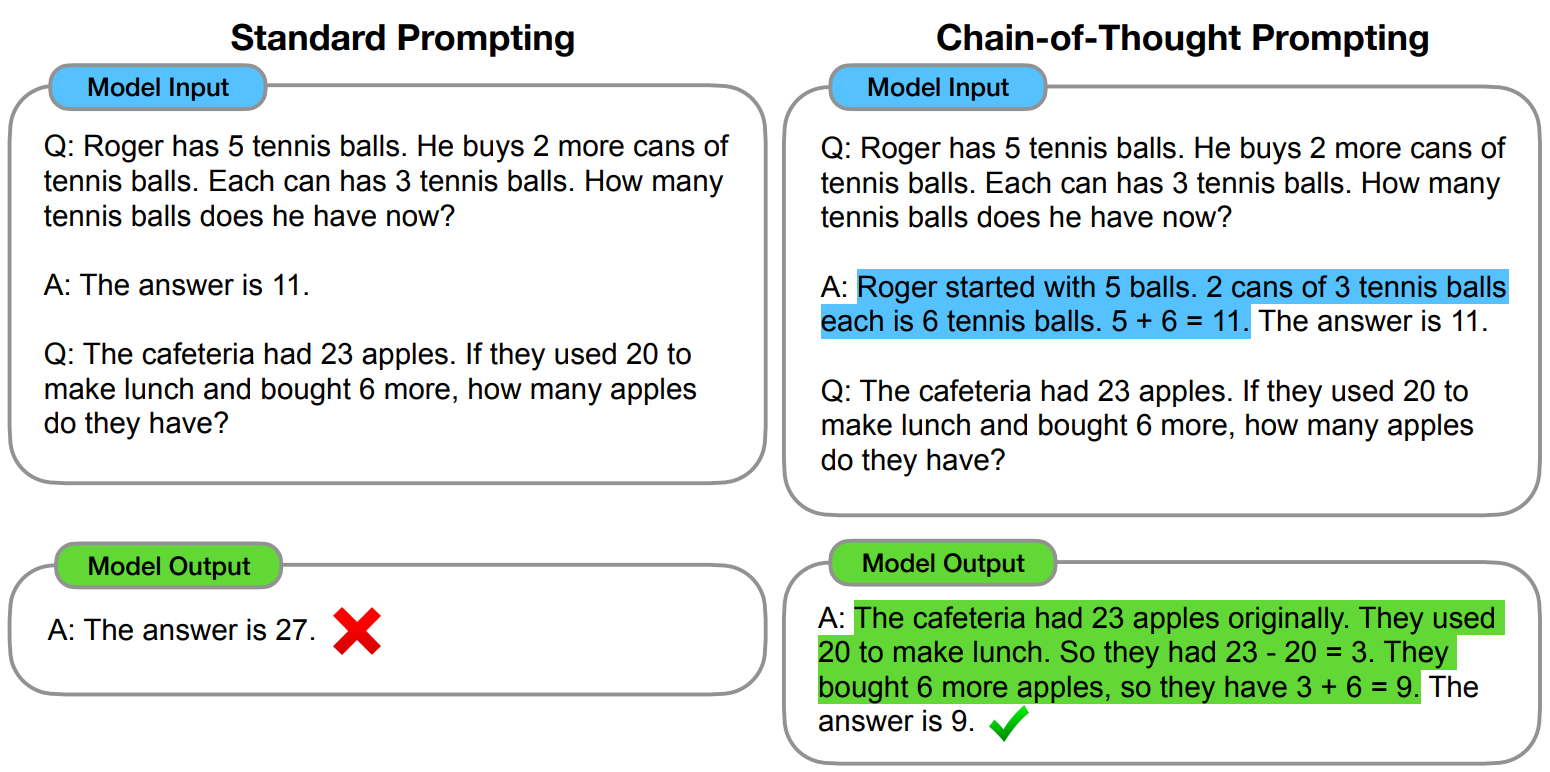
Today, they disprove conjectures that have remained open for decades.
So, all told, AI 2027 was an excellent forecast; given how detailed its predictions were, the rate of agreement with reality is just off the charts. As I said above, its qualitative predictions — agentization, the shift to "AI workers", the investment explosion, regulation falling behind, the safety problem turning from philosophy into empirical fact — are all essentially coming true. It's only the quantitative milestones that lag a bit.
The recursive loop of AI research is beginning to spin up: Claude writes 80% of Anthropic's code, AlphaEvolve speeds up its own training, a new version of GPT disproves an Erdős conjecture. But there's still some gap before a real singularity, a gap into which the answers to several important questions have to fit.
So far, bets against AI progress never work out; only bets against specific over-optimistic forecasts may be good. We shall see. We will watch the METR charts and the autoresearch benchmarks, but the main thing I'll be watching is my own experience, and how fast AI-assisted science moves. Watching—and hopefully telling you about it!