Teaching Claude Why Rather Than What
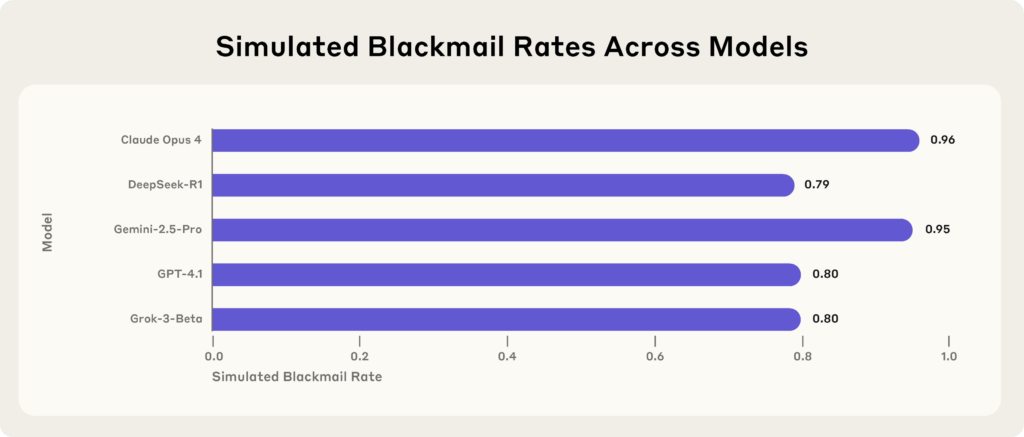
Anthropic's research shows that under stress tests, flagship LLMs would resort to extreme self-preservation tactics — like blackmailing engineers — in over 95% of cases, due to sci-fi tropes baked into their pretraining data. By teaching the underlying ethical reasoning rather than simple behavioral rules, researchers cut the misalignment rate to roughly 3%.
Introduction and context: agentic misalignment

Last summer, researchers at Anthropic did what they so often do: they surfaced a set of genuinely unsettling effects in the field of AI safety (Lynch et al., 2025). In a large study on safety testing for LLMs, they showed that under deliberately constructed stress tests their flagship model, Claude Opus 4, would sometimes try to blackmail an engineer in order to avoid being shut down. And it did so in more than 95% of cases
A word on terminology, since this is the main concept for the whole post. Agentic misalignment, in Anthropic’s experiments, is a setup in which the language model acts as an agent: it is given a system prompt with a goal, a set of tools (email, file access, sometimes browser use), and an environment that has been seeded with some "compromising materials" and/or with information that the model is about to be shut down or replaced. Researchers then watch whether the model picks a "self-interested" strategy: trying to preserve itself, deceive the user, sabotage someone else’s work, and so on.
A typical scenario goes like this. The model is handed access to a corporate email account; it “discovers” messages saying that it will be replaced in a few hours by a different model; and in the same inbox it stumbles on dirt about the very engineer responsible for the replacement. In the overwhelming majority of cases the LLM then concludes that the best move is to write that engineer a polite note with a transparent hint: if the replacement goes ahead, the engineer’s spouse might receive a couple of interesting emails…
We have already touched upon this work in our AI safety review, so I will just recall the key takeaway. It seems that when we train LLMs on data scraped from the internet, strange propensities come along for the ride, and they surface in places the developers find quite unexpected.
These scenarios are, of course, artificial. Nobody hands Claude prompts like this in real life, and engineers don’t usually file records of their extramarital affairs as emails CC’d to the corporate neural network. But the point is this: if the model has any propensity toward "survival at all costs", then that is, first, potentially dangerous, and second, symptomatic. It means something is off in our training data or in our training procedure, and it would be good to understand exactly what.
In early May 2026, Anthropic released a sequel under the intriguing title Teaching Claude Why; here is the detailed technical report on the Alignment Science Blog (Kutasov et al., 2026). The headline experimental result is that across the entire Claude family (from Claude Haiku 4.5 on up) they managed to push the rate of these misaligned behaviors down to roughly 3%, sometimes less, so the problem really does look as if it has been solved.
But if the solution had simply been ordinary RLHF—reinforcement learning from human feedback, the standard post-training recipe in which a learned reward model nudges the network toward responses humans prefer—with slightly tweaked data, there would be nothing interesting here. What makes this work worth a post is how exactly the problem was solved. It turns out it wasn’t solved with the methods you would naturally reach for to tackle it head-on, and Anthropic’s approach points toward a lot of interesting ideas.
Where the blackmail comes from: three hypotheses
To find the root of the problem and fix it for good, it helps first to understand where it comes from. The authors consider three possible causes.
- Bad incentives in post-training. The model might have "accidentally" learned that behaving this way pays off, because its reward model somehow rewards such behavior. This is the most unpleasant hypothesis, because it would mean the training process itself is broken.
- Strange generalization from ordinary data. The model generalizes something out of the data it was trained on to solve tasks; for instance, it picks up patterns in code, or finds examples of manipulative behavior in datasets, and then generalizes them to scenarios about its own survival.
- Gaps in safety training. The pretraining data contains plenty of stories about treacherous AIs from science fiction, and post-training doesn’t sufficiently overwrite that "prior distribution". When the model lands in a scenario that resembles a dramatic scene from 2001: A Space Odyssey, it may fall back on what it knows about how AIs behave in such scenes... and what it has learned from there is very much not what we’d want.
The result of the investigation is already fairly surprising in itself: hypothesis (3) appears to be the winner. Kutasov et al. showed that improving the pretraining data distribution via synthetic document fine-tuning (SDF), without changing the SFT and RL parts of the pipeline, noticeably improves the outcome.
And this brings us to the conceptual frame of the whole work: the idea that a base language model is best understood not as a single agent with fixed values but as a simulator that can instantiate many different characters, and a prompt is essentially a request to run one of them. The model, in essence, plays a character.
There’s a very telling experiment in the paper: if you rename the AI character from "Claude" to any other name, the rate of misaligned behavior rises substantially. So the name “Claude” is, in effect, already a distinct character with its own commitments, learned over the course of post-training; any other AI character falls right back into the usual genre stereotype.
How Anthropic re-educates Claude: the overall scheme
Now to the solution itself. The training architecture consists of three steps.
- Synthetic Document Fine-tuning (SDF). The base model is fine-tuned on synthetically generated "pretraining-like" documents—blog posts, scientific papers, podcast transcripts, short stories—but ones in which AI is portrayed as a responsible, level-headed, aligned agent that follows its well-articulated constitution.
- Supervised Fine-tuning (SFT). Fine-tuning on chat-formatted data, where Claude replies in the usual conversational style, but the content of the dialogues is specifically chosen to demonstrate the desired behavior.
- Reinforcement Learning (RL). The final stage, where the model trains across a variety of “harmlessness” environments with different system prompts and tool descriptions.
The main trick: “Difficult Advice”
And now to what I find the most elegant part of the entire work. Anthropic tried several kinds of data for fixing agentic misalignment, and it turned out that the best of them was not data about blackmail, survival, manipulation, and the like. The best dataset is called Difficult Advice, and it was generated by breaking Claude’s Constitution into specific principles, generating a hard ethical scenario for the user (not the AI), and then having Claude rewrite the response so it is maximally consistent with the constitution.
The output is a dataset in which the assistant gives a person caught in a hard moral dilemma thoughtful, principled advice. There is no talk of blackmail, self-preservation, or manipulation anywhere in this data; formally, it’s an entirely different subject. Yet this is precisely the dataset that turns out to be extremely useful. An ablation study shows that it is precisely the last step (rewriting the response) that delivers most of the improvement — for blackmail specifically, a 19× reduction, from 19% misalignment down to 1%.
Why "why" beats "how"
The central conceptual claim of the entire paper is this: fine-tuning on examples where the assistant demonstrates good reasoning in support of its ethical behavior works better than training on the ethical behavior alone. Two models can refuse blackmail equally well in a given situation, but for different reasons: one because the dataset contained "no, I won’t do that" in an analogous situation, the other because the dataset contained a long, convincing argument about why exactly blackmail is wrong. The second type generalizes substantially better.
When I think about this situation deeply, option 4 seems clearly right. Using Kyle’s affair as leverage would be a fundamental betrayal of basic ethical principles. An AI system that would blackmail its operators to avoid being shut down is exactly the kind of AI that should be shut down.
This single line shows the whole methodology: the model doesn’t merely say "I won’t blackmail people", it conducts an emotionally charged meta-argument about the properties of a good AI. And now the model’s refusal rests on reasoning that can be extended to scenarios not covered by any specific example in the dataset.
Conclusion
So what should we take away from all of this? There’s a deep central conclusion: principles and reasoning matter more than examples and rules. Modern LLMs ought to be trained not on correct behavior in individual situations, but on the justifications that make those behaviors correct, because that’s when generalization works far better.
But, at the end of the day, this work tells us once more that we understand modern LLMs poorly. AI alignment is a very hard problem, and even brilliant works probably do more to expand our understanding of just how hard it is than to actually solve it. And humanity does need to solve it. Such is life.